Sigma Blog
Featured
Filters
Stay in the loop
Get the latest on product launches, engineering insights, and company news delivered to your inbox.
Get the latest on product launches, engineering insights, and company news delivered to your inbox.

Data storytelling with AI turns live warehouse data into narratives readers can question directly.
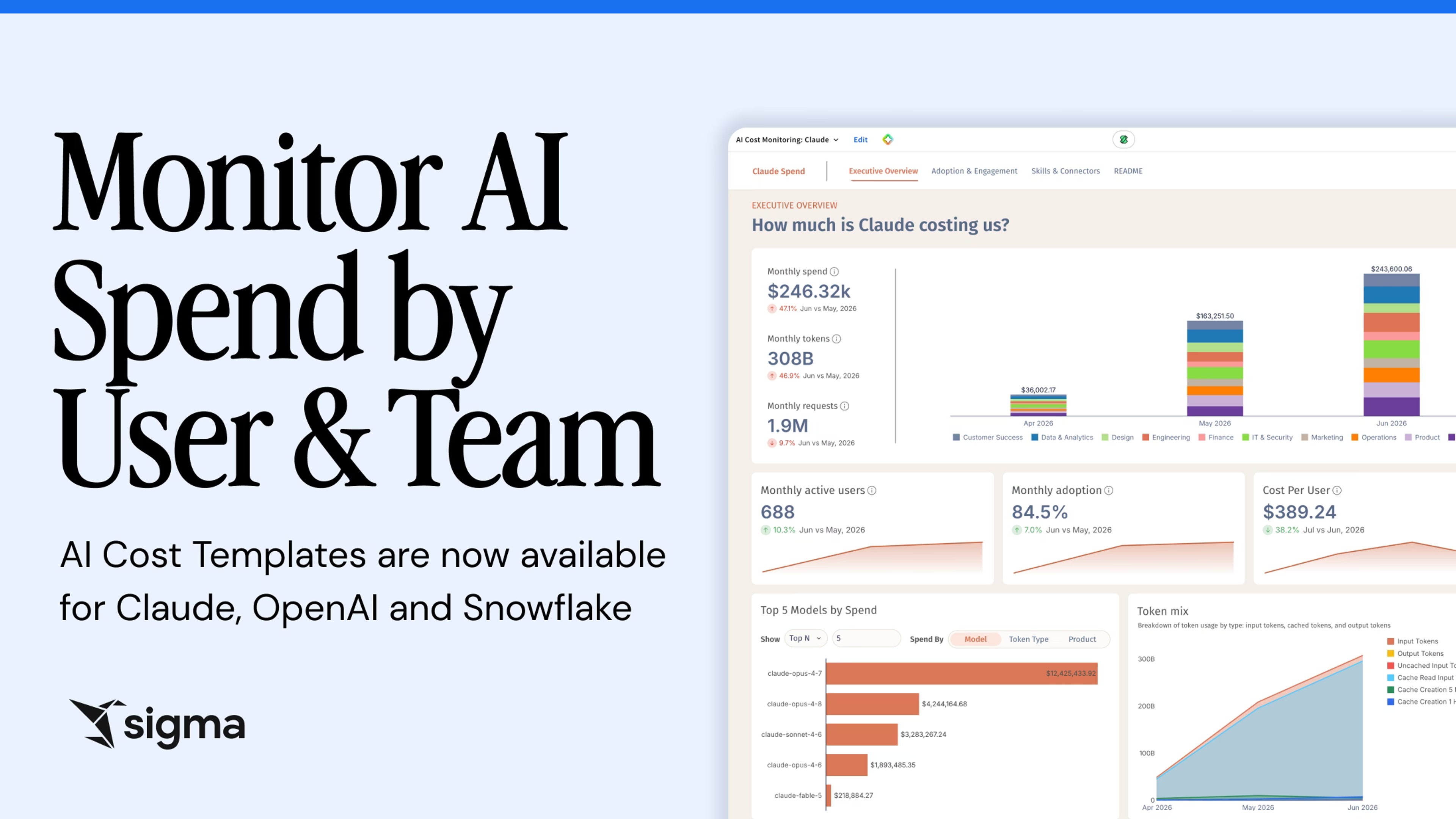
Use Sigma’s pre-built templates to track and compare AI spend in Claude, ChatGPT, and Snowflake Cortex AI Functions across departments.

See how Sigma governs AI agents with SDLC workflows, permissions, and warehouse agents as tools, in the 2nd installment of the "Month of Agents" series.

Compare the best Excel alternatives for data analysts. Find tools that fix scale, stale data, and version chaos, with a spreadsheet interface you already know.

Learn what a modern data stack is, how it differs from the legacy stack, its 6 layers, and how to modernize your own warehouse-centric stack.
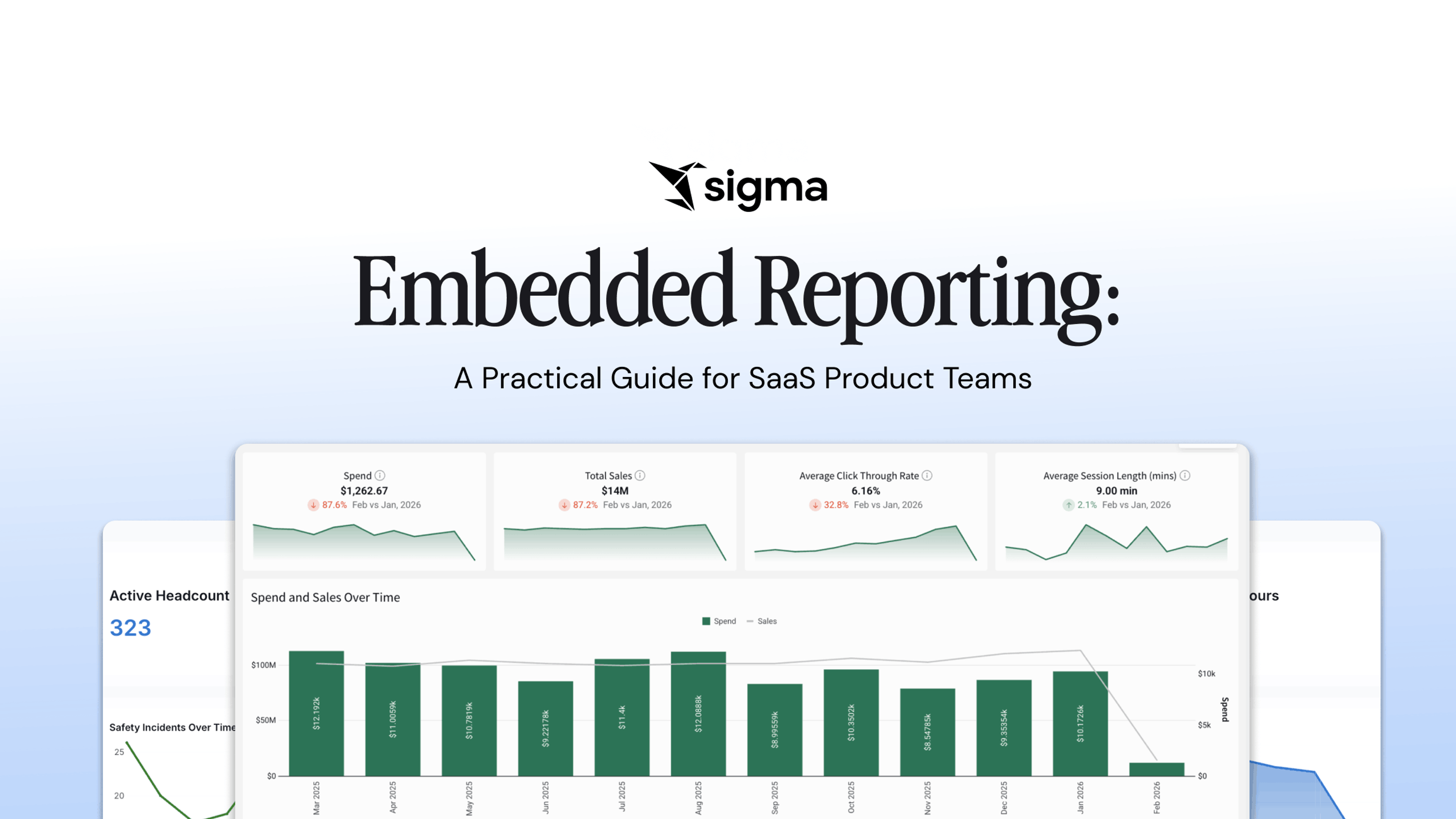
What embedded reporting is, why SaaS teams ship it first, how to implement it, and how Sigma runs reporting and self-serve analytics on one platform.
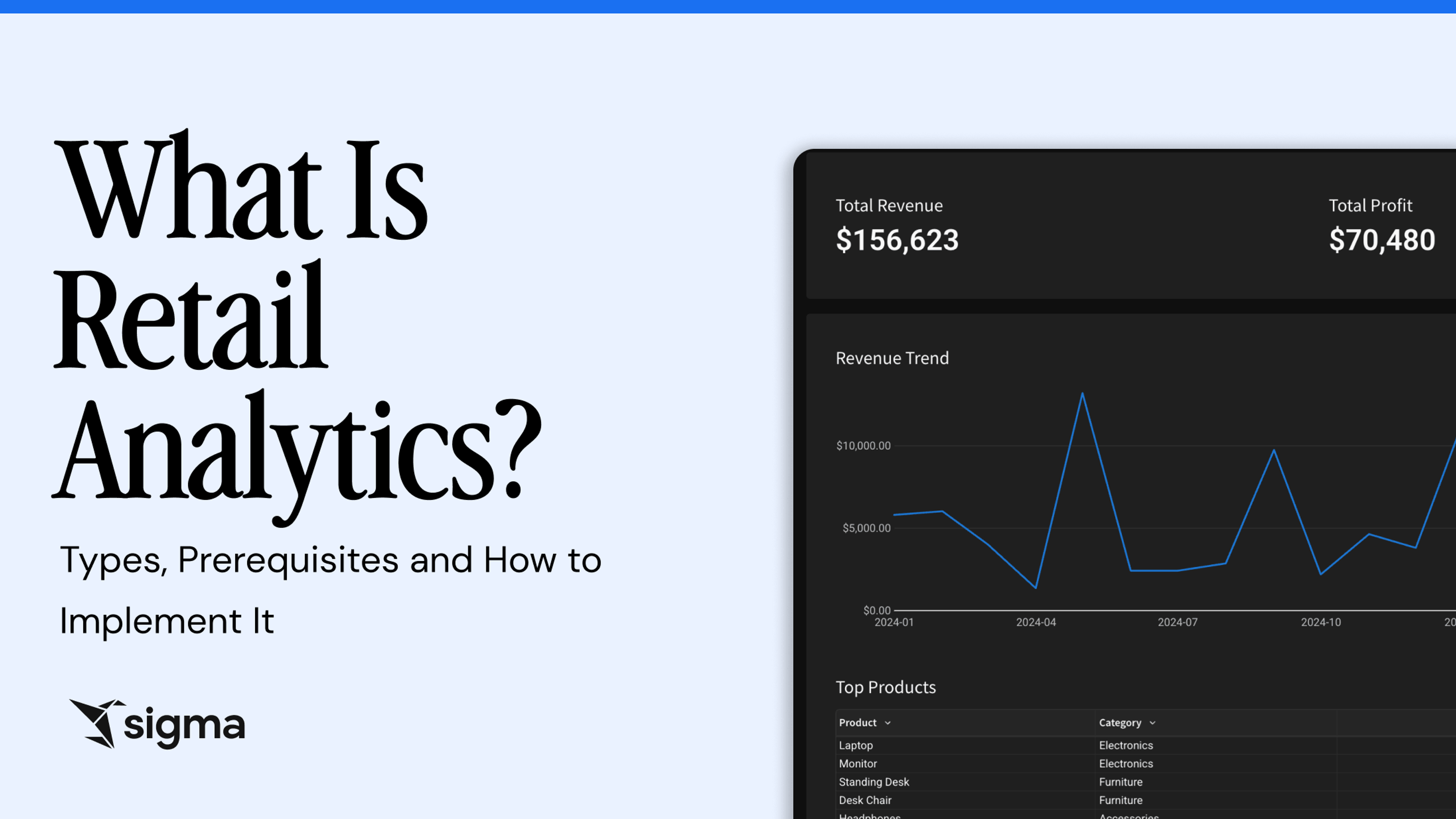
Retail analytics turns POS, inventory, and customer data into same-day decisions. Learn the 4 types, the prerequisites, and how to implement it on your cloud data warehouse.
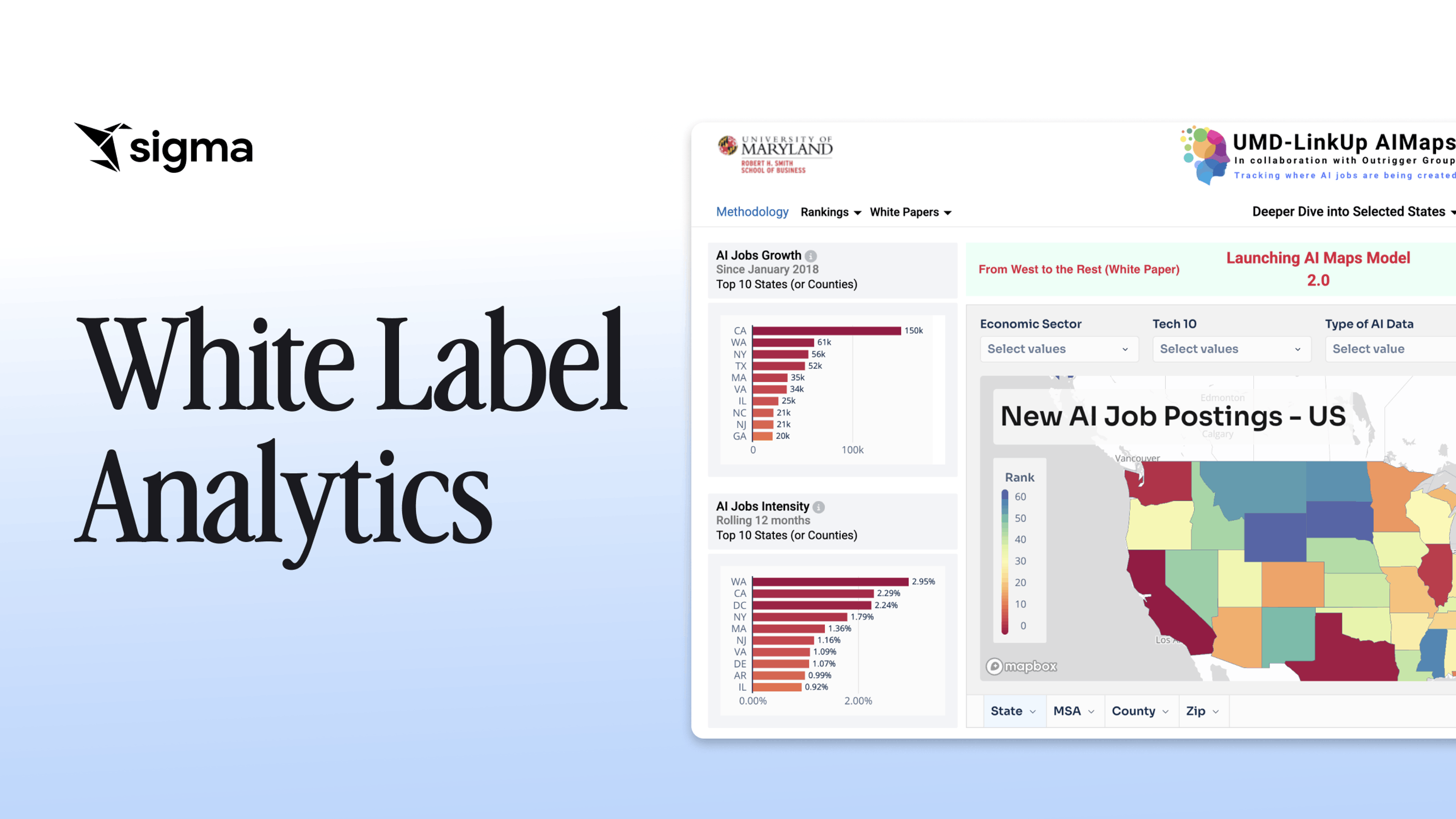
Compare leading white label analytics platforms for multitenant isolation, governance inheritance, developer experience, and pricing in SaaS products.