The Potential of Predictive ML Models in Sigma

Here’s what happened when we combined the machine learning models of Snowflake with the flexibility and cloud-nativeness of Sigma.
Spoiler alert: Amazing things are suddenly possible.
From my first days at Sigma, I started exploring ways that we could use the flexibility of the Sigma interface to use data science models directly through and from the cloud data warehouse. Fantastic work done at Snowflake on its Snowpark Platform has opened up the possibilities of registering open-source models into saved models within the CDW. Combine that with the strength and flexibility of Sigma’s connection to Snowflake, and we arrive at an exciting conclusion:
Business users make use of the models they need for their work—within the same tool they are doing the rest of their analyses—live on the data that is relevant to them.
This makes the exclusive Data Science domain of robust, real-time, model-scoring possible in a BI platform and available to every business user across an organization.
Score, Analyze, and Decide!
The Typical Machine-Learning Workflow Space Today
There are a few ways to present the results of ML models. That format could be visualizations, which help to communicate the performance and predictions of a model to stakeholders. Or that format could be BI analytics, used to monitor the performance of a model over time and identify any issues that may require attention.
In discussions of this workflow with a number of our commercial partners, I learned that many organizations deploy their models in roughly the same way:
- Model is written, trained, and saved on a local machine or third party vendor.
- Data is run through this model and scored to create relevant output variables (e.g., A company might run a model to determine whether or not an applicant is approved for a credit card).
- Output files generated by the model are then uploaded to the server side of the BI tool in order to be visualized.
Often, this cumbersome workflow exists only because of technical limitations. And while functional in the most straightforward sense, it brings many weaknesses to an organization. I was able to identify five significant business consequences that were limiting our partners:
- Delayed decision-making: The delay caused by having to manually push model output files to a BI tool often leads to delayed decision-making, as the data isn’t immediately available for analysis.
- Lack of real-time monitoring: Without the ability to live-score data in a BI platform, organizations are unable to monitor their data in real-time, which can lead to missing important trends or issues as they occur.
- Limited automation: If model output has to be pushed to a BI tool, organizations may not be able to fully automate certain business processes, such as data-error detection or predictive maintenance, which can lead to increased costs and inefficiencies.
- Limited scalability: Without the ability to live-score data in a BI tool, organizations may have limited scalability when it comes to data analysis, as they may have to rely on manual processes to handle increasing amounts of data, such as partitioning the data.
- Limited data product offering: Without the ability to live-score data in a BI tool, organizations are further limited in their ability to provide modern, sophisticated data offerings like customer recommendations or live predictions in their customer-facing products.
Read more about Sigma AI here.
Example Use Case
Imagine that you work for the technology retail company PLUGS, and you are interested in exploring the model that the company uses to approve customers for its exclusive Loyalty Program. You’ve been told that only the best of the best get approved for the Loyalty Program and its generous perks, and as an analyst charged with exploring the kind of impact this may have on PLUGS revenue, you are certainly interested in exactly who “the best of the best are”.
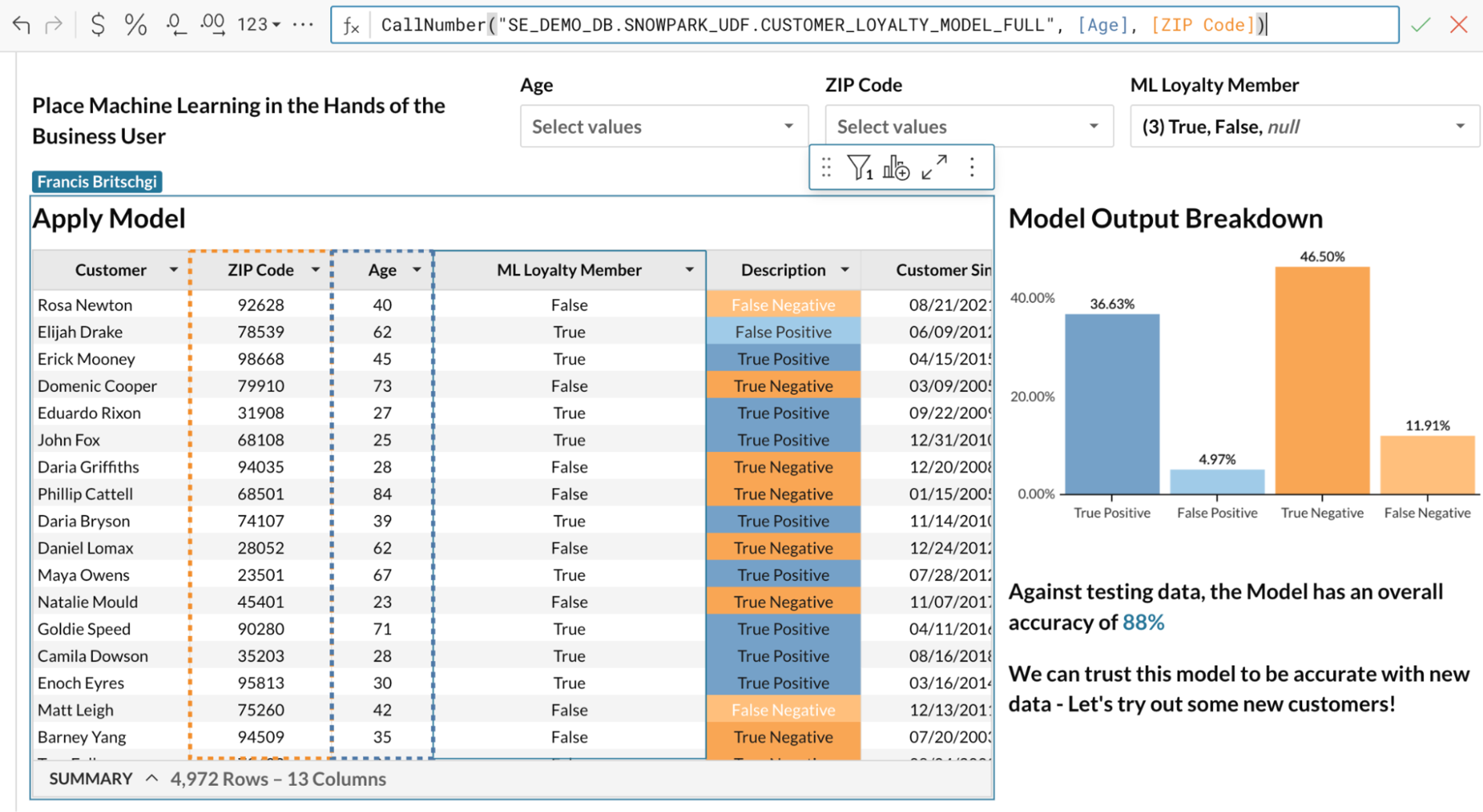
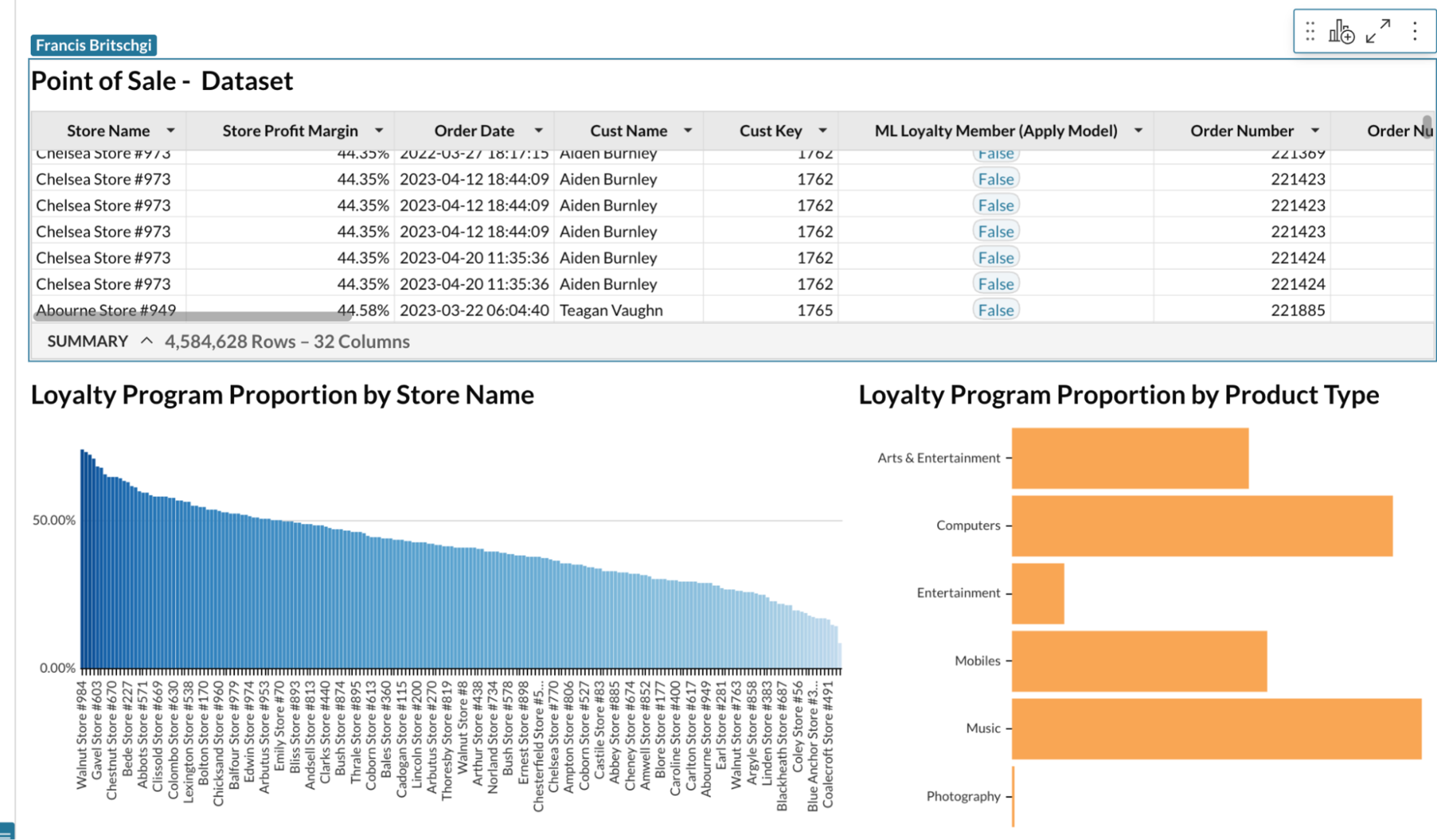
Thanks to Snowflake’s Snowpark, your Data Science team has been able to develop and register that model in Snowflake, alongside your customer database. As a result, the organization now has access to that model through Sigma’s Pass-Through functions—in other words, they can call their ML Loyalty Model, just like any other Sigma function!
Now that we have access to the Loyalty Program determination for all customers in the dataset, our next steps are as open-ended as the entire Sigma platform. We can build visualizations to plot out Easy-to-Understand charts in order to thoroughly understand the accuracy of our model. For an example, we can plot the rates of True Positives and True Negatives, where test customers were accurately categorized.
Apply Model
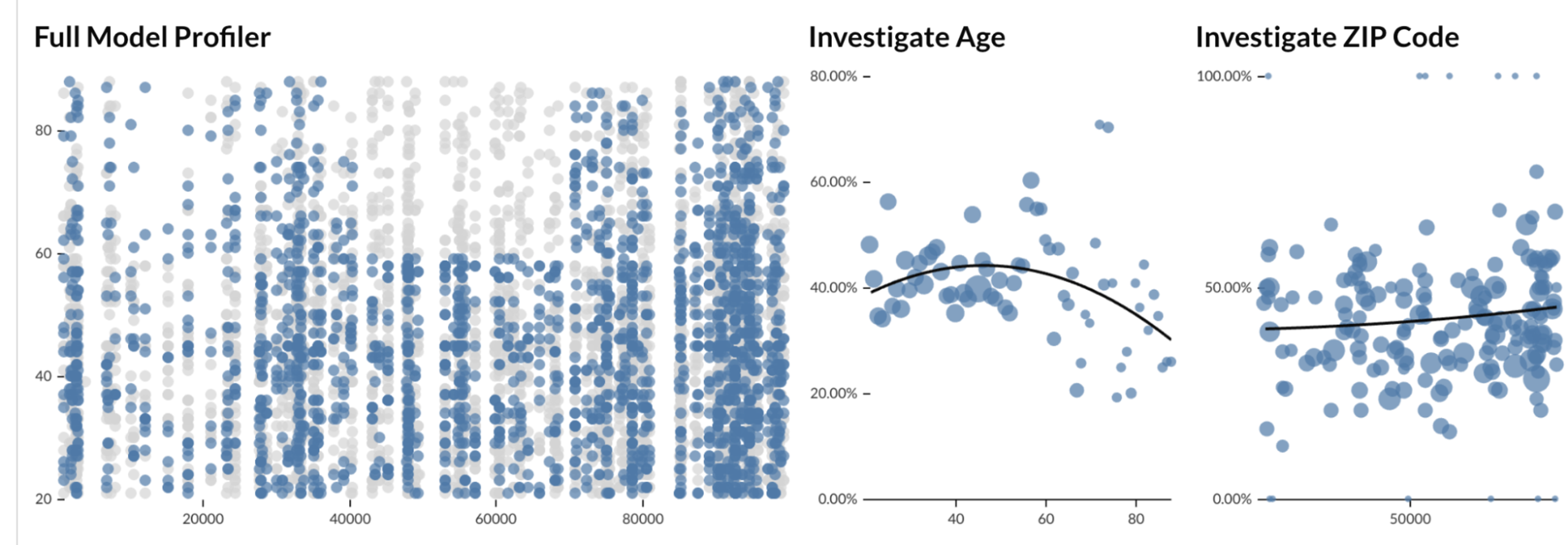
Or we may be interested in how our model assesses people around the country or across variables not included in the model, like gender. This is a critical aspect of model validation and ensures ethical models.
Model Audit

Or perhaps we want to explain to a high-level stakeholder how the model works—or how the effects of the model express across a single variable, like age. We can clearly see that age doesn’t have much of an effect until the elderly, at which point the model begins to exhibit a clear bias.
Model Profiler
Or maybe we want to make use of Sigma’s easy-to-run Joins and pull in data on 4.5 million rows of retail sales to analyze the customer profile of each store that we’ve sold in—we may be interested in predicting how different stores and their product offerings may support different loyalty groups!
But the best synergy between Sigma and Snowpark can be found in Sigma’s Input Table functionality, where users can input brand new data directly alongside their CDW data. Input Tables revolutionize the way business users can interact with cloud scale data, and we can apply the same benefits to their interactions with data science tools. As a result, business users can instantly see the impact of governed models on hypothetical data.
Method
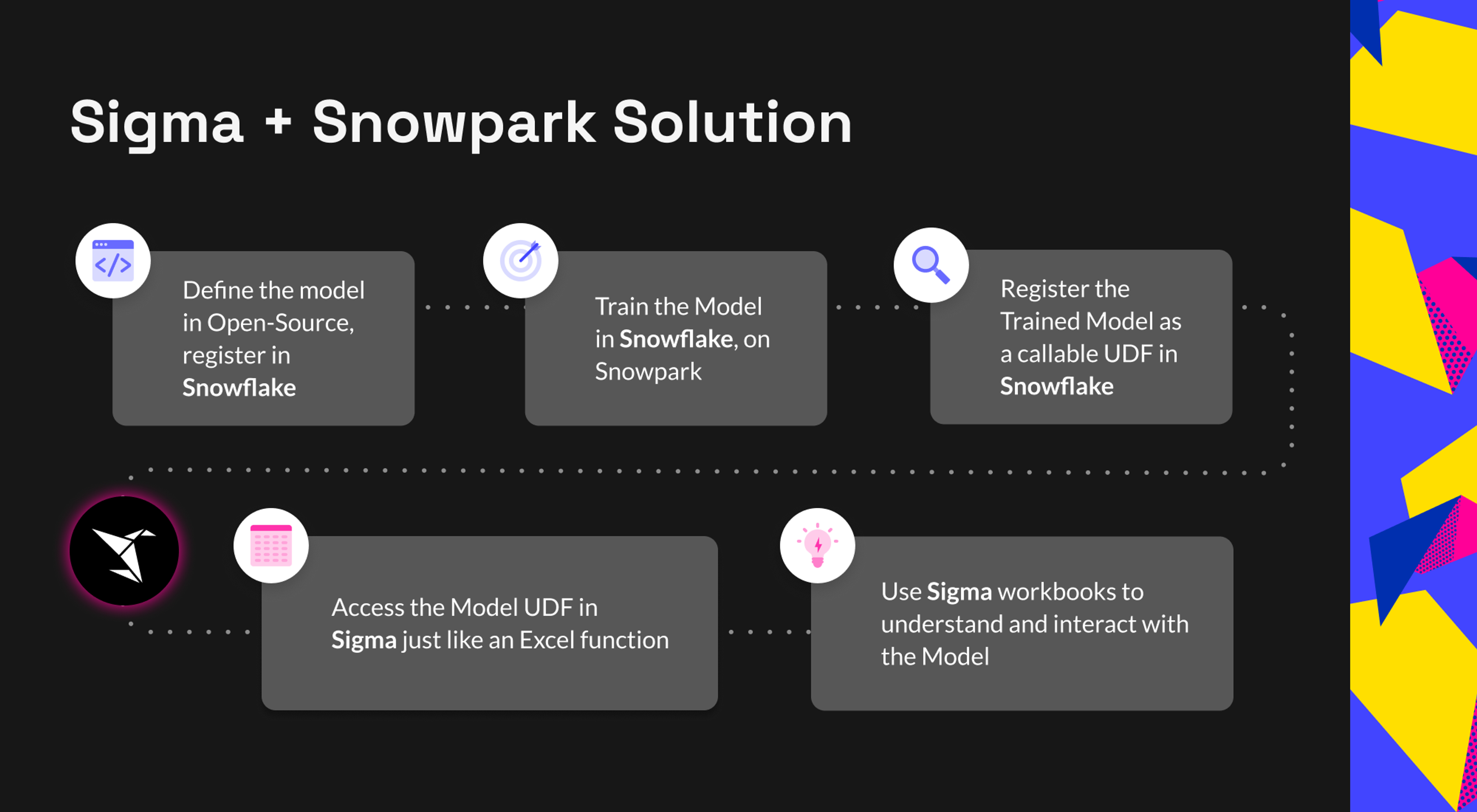
Thanks to the direct connection between Sigma and Snowflake’s Snowpark, the framework already exists for establishing a live-scoring system within Sigma itself. Here’s how you can make it happen:
- Use Python to define, register, and train the model natively in Snowflake with the Snowpark developer framework, allowing for the use of the model within the Snowflake platform. Snowflake has built an excellent QuickStart resource to walk you through the process.
- Create a UDF (User-Defined Function) in Snowflake that allows organization members to use the model on new data, making the model accessible and usable for a wide range of users.
- Access the UDF through a Sigma Pass-Through Function, allowing the model to be used for creating Sigma Workbooks and Datasets.
- Build out your first workbook in Sigma to assess the model and its results, providing visibility into the performance of the model and making it easy for stakeholders to understand and interact with the data and the model.
These steps provide a balance of flexibility, scalability, and governance, while also making sure that the model is accessible to the users who need it and providing visibility into the performance of the model.
Conclusion
In short, we have formalized a methodology for real-time model scoring without ever having to leave the BI platform—all while remaining within the governed framework of a Snowpark-deployed model in Snowflake. The extensions and applications of this methodology go far beyond the imagination of the author—a proposition that eagerly awaits the input from Sigma users across the world! As a start, I would love to address the limitations that were listed earlier in this article, adjusted to reflect the realities of a Sigma + Snowpark solution space.
- Real-time decision-making: The scored data is immediately available for analysis, eliminating the delayed decision-making caused by manual model push methods.
- Real-time monitoring: The ability to monitor the data and model outputs enhances your business user’s live view of important trends and issues. Alerting will be done at the instant that new data enters the system.
- Enhanced automation: With direct model output, organizations enhance the ability to automate certain business processes, such as data-error detection or predictive maintenance, giving your team further ability to decrease costs and time-heavy operations.
- Full scalability: When the model runs directly within the CDW alongside the data, organizations will not face the limited scalability inherent in a local-scoring methodology, where they may have to rely on manual processes to handle increasing amounts of data, such as partitioning the data.
- Enhanced data product offering: With the ability to live-score data in a BI tool, organizations are further empowered by Sigma in their ability to provide modern, sophisticated data offerings like customer recommendations or live predictions in their customer-facing products.
Request a demo of Sigma or set up a free trial.