Why We Built Sigma’s Worksheet

May is the month of Sigma Computing’s founding. So it’s a good time for us to reflect on where we are going and how we got here. Sigma is a startup founded with a goal of making data within organizations more usable to its members. Sigma Worksheet is our innovative, direct-manipulation interface enabling visual, interactive online analytical processing (OLAP) at cloud scale. It is designed for analysts and business users alike and is the foundation upon which Sigma is built. However, before we converged on Worksheet, we had to learn what its properties should be through a series of experiments. Here we share some of that journey and the lessons learned.
Automated Insights
Initially, we built several prototype analytic systems whose functionality might be summarized as “automatic query generation.” These required a semantic model of the data, so we experimented with different automatic and manual systems for constructing that model. For data ingestion we built integrations with several Software-as-a-Service (SaaS) platforms.
As a test case, we used sales and operational data from a large technology company and tried to automatically generate the reports they were producing manually. We evaluated these results through interviews with the people who had produced the original reports.
From this work we gained many insights, among them:
Automatically producing valuable analyses for our customers was going to require a heavy investment in up-front modeling. We knew this would make sales difficult and expensive, and furthermore, it didn’t feel like who we were. We wanted to offer information superpowers to our customers, not IT consulting projects.
Enterprise data comes from a huge number of sources. We wanted the experience of onboarding with Sigma to be seamless, even delightful for our customers, but building a high-quality integration for every data source a customer cared about was daunting for a small company.
Capturing company-specific knowledge with automated methods proved difficult. For example, negative sales amounts were outliers and seemed to offer interesting insights, but they actually just represented equipment returns.
Our systems put the business user, along with their knowledge, on the sidelines. If our users saw something that looked wrong, they had no practical way to correct or revise it, especially if they couldn’t understand how values they saw were being derived. As automated methods powered by AI become popular again, we believe these early lessons are as pertinent as ever.
Visually Programming Data
Reflecting on these prototypes, we began exploring how to capture and automate the knowledge of business users. We observed that many contemporary analytics systems such as Tableau provided an interactive visual interface, but still required some coding proficiency in practical use. We believed that a sharp drop-off from the visual interface to the programming layer hinders the productivity of end users. Every time the code needs a change, the business user becomes blocked on someone else who can update the code. Worst case, the user might have to do without that change, leading to incomplete analyses. Interviews with current users of these systems confirmed this belief. So we asked ourselves: can we integrate code with a visual interface tightly enough to enable business users to become programmers?
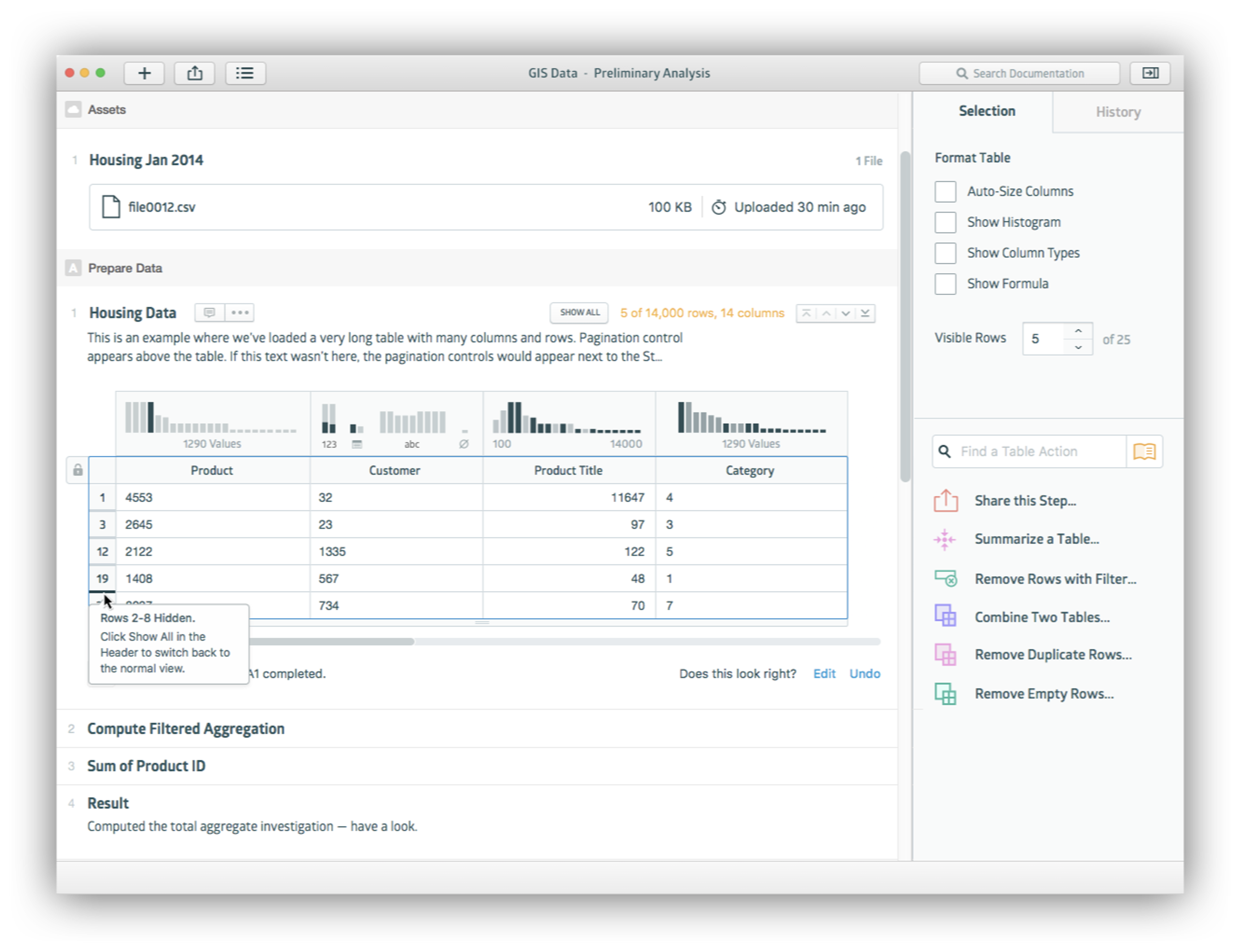
Motivated by this question, we implemented a series of prototype systems that presented data and code together and let users manipulate both using an interactive visual interface. Our interfaces were “live” in the sense that they automatically refreshed values in response to changes, inspired by electronic spreadsheets, functional reactive programming, and Bret Victor’s learnable programming. We also drew ideas from data-wrangling systems, including Wrangler and OpenRefine, and end-user code-synthesis approaches such as Excel’s Flash Fill.
We experimented with several interface forms: a spreadsheet-like canvas, interactive histories of transformations against data, and notebook-like documents similar to Jupyter. We also tried two novel functional programming languages, first a simple record-based language and later an array-based language. Both were influenced by Excel formulas and Microsoft’s M language (evolved to Power Query in subsequent years). We investigated the usability of this platform with our own use-cases and with feedback from analysts and business users in our target markets.
From the development of this second category of prototypes, we learned some hard lessons:
Matching a live execution environment with an unconstrained programming language was a challenge. Everything looked beautiful in Bret’s demos, but in our actual usage we saw how a very small change in the code could lead to an arbitrarily complex change in the data. In an environment where the view reacts to the code and the data, this means that the user’s view while editing can become unstable and disorienting.
Complex operations were difficult to integrate into a guided user interface, alongside arbitrary code. Our query language was powerful, but we know many users wouldn’t be comfortable using it directly. We needed to provide special-purpose interfaces to guide users through important and complex operations like joins and grouping, but our efforts to mate a special-purpose interface to arbitrary code was only partially successful.
Potential customers were reluctant to entrust direct access to and storage of business data to a brand-new cloud-based organization with no reputation. We believed strongly that the cloud was the future for IT and were determined to build our product there, but the reality is that SaaS companies survive on trust — something that we had not yet earned.
Design Considerations
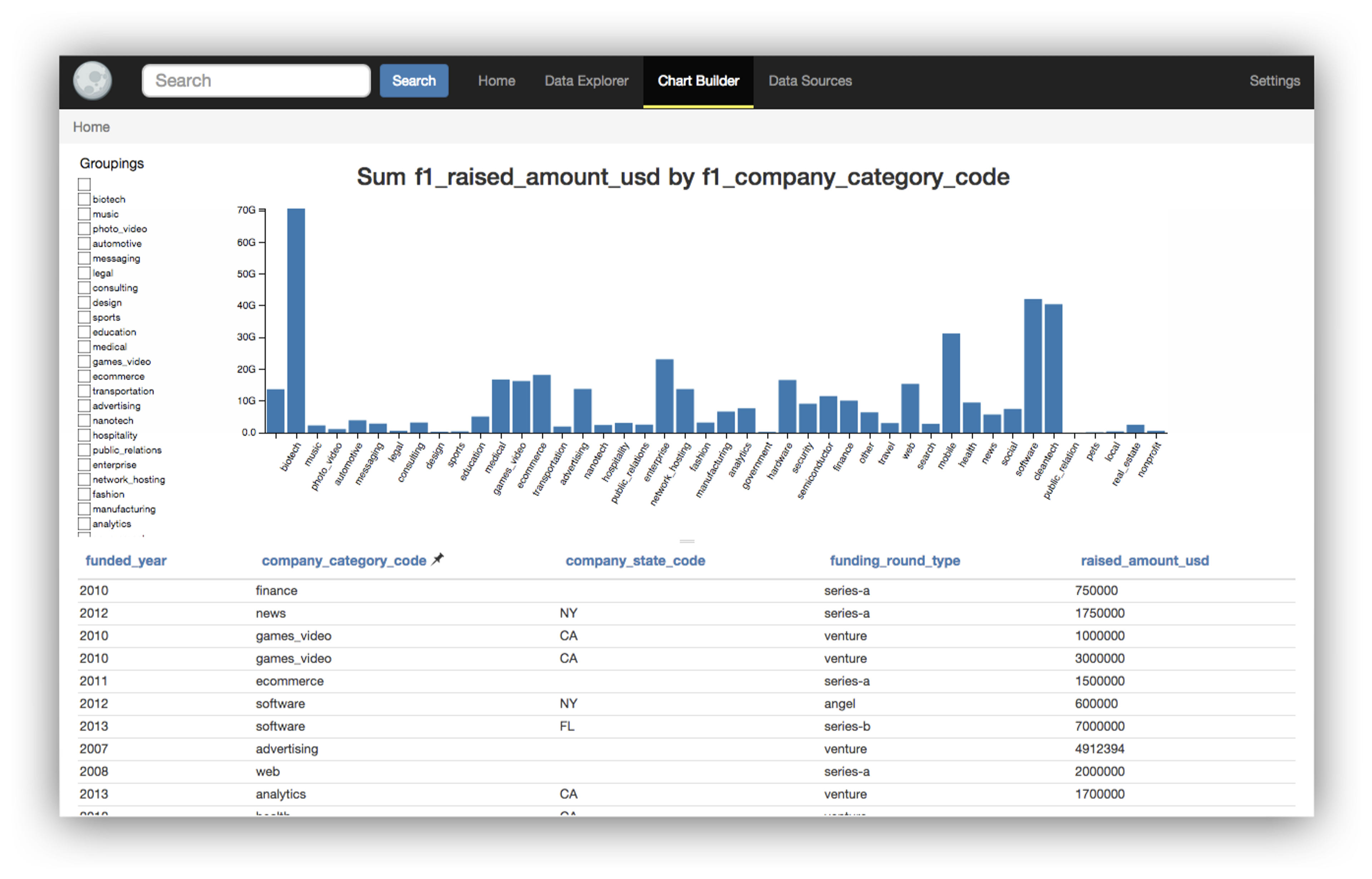
After these iterations and experimentation, we set out to build Worksheet, the interactive query builder that would underpin Sigma. We were seeking a middle ground between the two types of systems we had previously explored, a highly-automated system with very limited interaction and a visual programming system. We identified five criteria for Worksheet’s design and development, informed by what we learned from our earlier iterations, existing research and tools for data analysis (in particular Eirik Bakke’s Sieuferd), and our experience in developing data systems over the years:
Build on the data warehouse that customers already have. Avoid a lengthy ingest phase, endless third-party integrations and data controller responsibility. The new generation of cloud data warehouses (CDWs), such as Google Big Query, AWS Redshift and Snowflake, enable a direct-query model for business intelligence (BI) that wasn’t viable in the old on-premises world.
Enable data experts and business users to collaborate in a shared language. The interface we offer for business users must bring the full power of the underlying database.
Allow business users to share and automate their knowledge. The system must support composition and parameterization in ways all our users can understand.
Make the query model a good match to a live visual interface. The user’s view must not change in unexpected ways when they are making edits, and complex changes must be guided by purpose-built interfaces.
Design the query builder to be understood and used by anyone who can use spreadsheet systems. Spreadsheets have well known deficiencies, but they haven’t stopped Excel from becoming the world’s #1 BI tool. We decided early on that Sigma was for all business users, not just analysts and data scientists. We want to meet these users where they are, allowing them to transfer hard-won spreadsheet skills to the data warehouse.
Conclusion
From the very first demonstration of our Worksheet prototype, we saw that it would be the foundation of Sigma. Fast forward and Worksheet now makes cloud-scale data accessible to all Sigma users — many with little or no prior experience working with databases. Worksheet enables them to engage with the data they care about in an interface that is both familiar and productive.
This article is an adapted excerpt from a paper detailing and studying the design of Worksheet. Continue with the full paper on arXiv to learn how Sigma Worksheet works “under the hood,” or watch this short demonstration video to see Worksheet in action.
Thanks to Eran Davidov