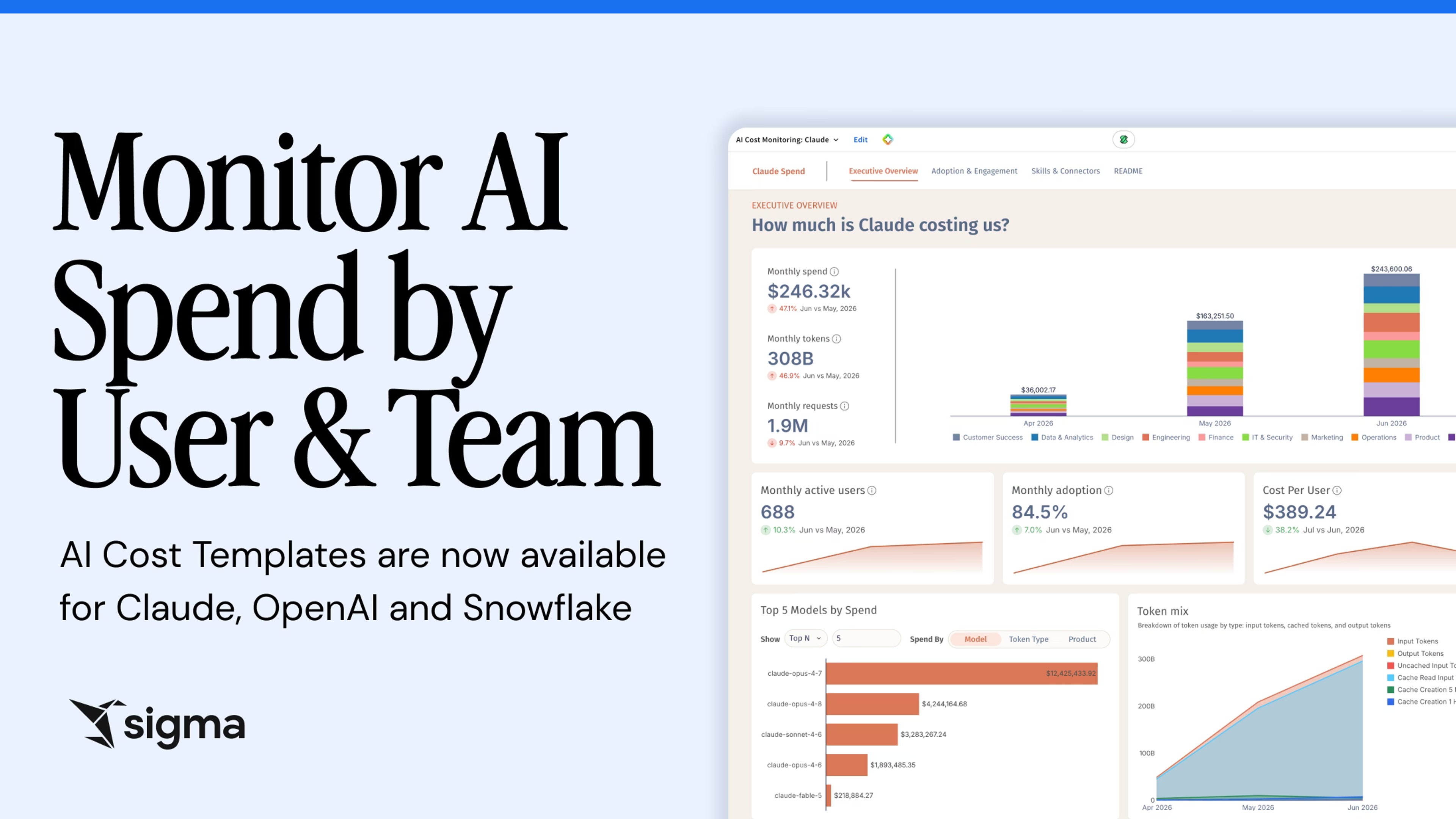
We're Misreading the AI Bill
For two years, companies threw money at AI. They knew they had to be AI-first, and this spring, they got there almost overnight. Nobody planned for adoption to arrive that fast, or for the spend that came with it. The first big bill turns enthusiasm into scrutiny, and every executive I talk to is asking the same thing: How do we measure the ROI? The agents run around the clock, the people who used to ask a chatbot a question now set loose agents that work on their own, and the meter never stops. What used to be a fixed license is a variable charge that climbs every month. People are not wondering whether they should use AI, but rather, how can they measure it and use it efficiently.
Plenty of tools can report your token usage, but none can tell you whether it was worth it, because worth doesn't live in a token counter. Did the engineer actually ship faster? Did the rep close more deals, or did support clear its backlog any quicker? A token counter sees the cost, not the return.
There's no single formula to hand people, either. Finance, engineering, and sales each measure return differently, and each wants to dig in on its own terms. Teams that can answer "is AI paying off?" keep investing with confidence while everyone else is hitting the brakes.
What it takes to answer it
To be able to answer the question of payoff, you need two things: (1) all your enterprise data in one place, and (2) the freedom for anyone to build and reshape the analysis themselves, without waiting on an engineering backlog.
Our job, as we see it, is to shift the focus from the token meter to whether the token spend produced anything useful.
The cost that comes after
Much of the spend produces one-off answers, while the ad hoc bill climbs into thousands a month per person. Ask the same question dozens of times, and you pay dozens of times, but build it once as a dashboard, and you pay once.
That same logic has convinced a few teams they can skip the platform and generate the dashboard themselves, and to be fair, generation really has gotten cheap because a good engineer with a coding agent can stand up a dashboard app for a couple of thousand dollars in tokens and an afternoon of work.
But generating it was the cheap part, and the dashboard still has to run somewhere. Someone has to hand-build the layer underneath it, the exports and the permissions and the version history a platform would otherwise handle. You set out to skip the workarounds and end up writing your own runtime layer one workaround at a time.

After that, the requests never really stop, and each one is its own small job: a new column, a corrected metric, or a filter for the West region means a fresh agent run plus an engineer to review the pull request and keep the GitHub governance from rotting. The salesperson can still fire off a throwaway query on her own, the way she always could, but the moment the answer has to leave her laptop and reach a customer or a board, it routes back through the central team and waits in the same queue as everything else. Every change to the dashboard now costs a model and a person, which is a strange place to land after buying software to get away from exactly that.
By itself, the build number only ever covered version one, and the recurring half of the cost shows up afterward: the monthly work of changing and refreshing the dashboard, and the engineers you keep on staff to maintain it.
A small tech company with engineers to spare can absorb that and barely feel it, but a normal enterprise can't, because absorbing it means insourcing the whole research-and-maintenance budget a vendor would otherwise carry, and almost nobody signs up for that on purpose. The math only works if your needs barely change, if you're content with static dashboards forever, and you have an engineering team with time to spend on security and infrastructure of your vibe-coded dashboard.
The AI spend that pays off
The value of enterprise AI is applied to the action that follows the generated artifact. A system should change when the thing it runs on changes. That only happens when AI runs on your own governed data, right next to the AI models, with agents that take action and write data.
If only the data team could build them, you would get one or two agents in production and a long queue behind them. The most valuable agents are those that are built by business teams because they are so close to the problem. It's the analyst who knows which campaign matters, and it's the person in finance who knows how the close really works. Most of them don't think in SQL (and they shouldn't have to). Give them the ability to build an agent in plain language, make sure they can connect it to a spreadsheet of data, and that's all they need to finish the job.
Hand that power to everyone on raw data, though, and you get the other problem. Your best people go from 10x to 20x, and your weakest go from 1x to 0.5x, churning out slop with confidently wrong answers and code no one wants to read. And even worse, that slop costs you nearly the same amount in tokens as your most effective employees are spending.
You're not going to turn every team into a 20x-er. But when it comes to working with data, you can put guardrails in place that reduce the slop and safeguard against repetitive, unnecessary token runs. The first fix is to make sure your team is using AI with governed data, in a secure system where you define your data models and metrics once, so any question about revenue returns the number the company agrees on, not whatever the model found lying around. The same self-service that drives adoption has to run where the definitions and permissions already live.
I'm not recommending spending less. You can never slow your teams down to save money. Instead, we need to ask how to scale our current, and growing, spend as we have done with software and hardware for many decades. We need to make the money produce more for our business (reduced OPEX, increased revenue). This concept, the change in conversation from "should we use AI?" to "is it efficient?" is happening at every board meeting. Once you get trusted AI and governed data into the hands of the people closest to the work, then you can answer that question.