Input Tables Deep Dive Part 1: Translating Spreadsheets into SQL
Input Tables
At Sigma, we like spreadsheets. We've designed our product to look and feel like a spreadsheet even though it's backed by a cloud data warehouse that can handle billions of rows. Sigma translates the formulas in your spreadsheet into SQL queries and sends them off to data warehouses to read your data.
But reading is, at most, half of what spreadsheets can do. We like spreadsheets because you can play around with them: you can clean up data, test out different scenarios, and change the meanings of whole columns on the fly. They're quick and easy digital scratchpads that just let you get things done (as long as your data is small enough).
Unfortunately, there are lots of cases where the data you want to play around with is too large for a spreadsheet. If you have data at the scale of a cloud data warehouse and just want to fix a typo or check what sales will look like next quarter if you win or lose a particular deal, you're basically out of luck. Your choices are to set up a full-scale ETL pipeline to make a few tiny changes or to extract a subset of your data from the cloud data warehouse and put that subset into a spreadsheet. If you go the extract route, your data is now outside the source of truth; you're only looking at part of the data, your data gets stale, it's hard to share your work, etc.
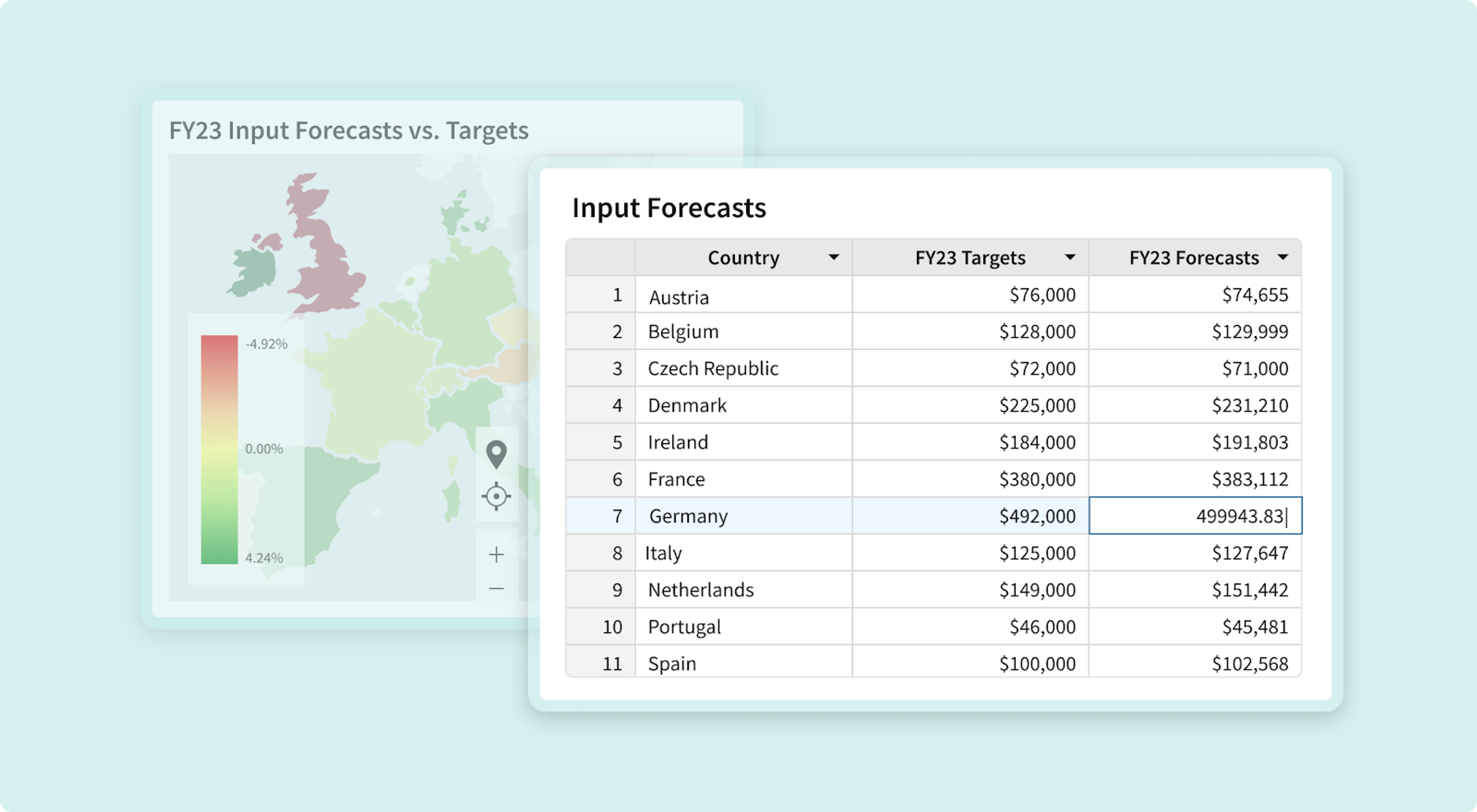
We realized there was a missing tool in the data toolbox: something that would make writing a small amount of data back to your data warehouse as easy as typing it into a spreadsheet cell. So, we decided to build that missing tool, which we call an input table. Input tables look like spreadsheets, but when you add data to one, Sigma pipes that data directly into a table in your CDW.
There's a lot of technical complexity that goes into making a data warehouse act like a spreadsheet. In this series of blog posts, we're going to walk through some of that complexity and how we addressed it. For this post, we'll cover the first problem we needed to solve to get input tables working: translating a spreadsheet's "grid of cells" data model into SQL's "bag of rows" model.
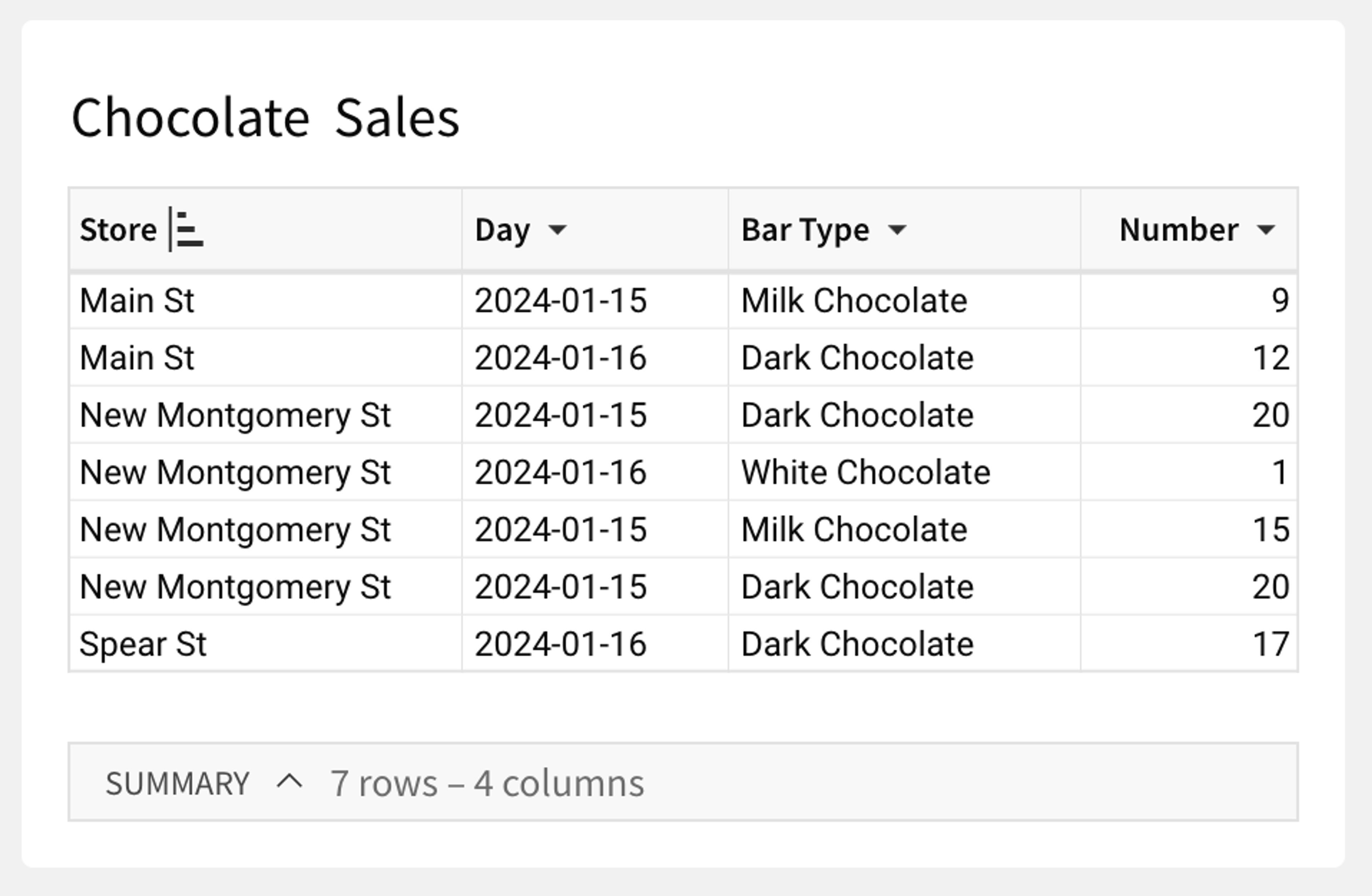
An SQL warehouse models your data as an unordered bag of rows. Every time you query your data, you have to tell the warehouse how to pull rows from the bag: which rows to select, which columns you want from those rows, and what order you want the rows to be returned in. Critically, you can only select and order rows based on the data they contain; there's no global "row number" to tell you which row is which or what order they should be in. If multiple rows have the same value for the column you want to sort on, the warehouse doesn't have to give you those rows back in the same order every time you query it.
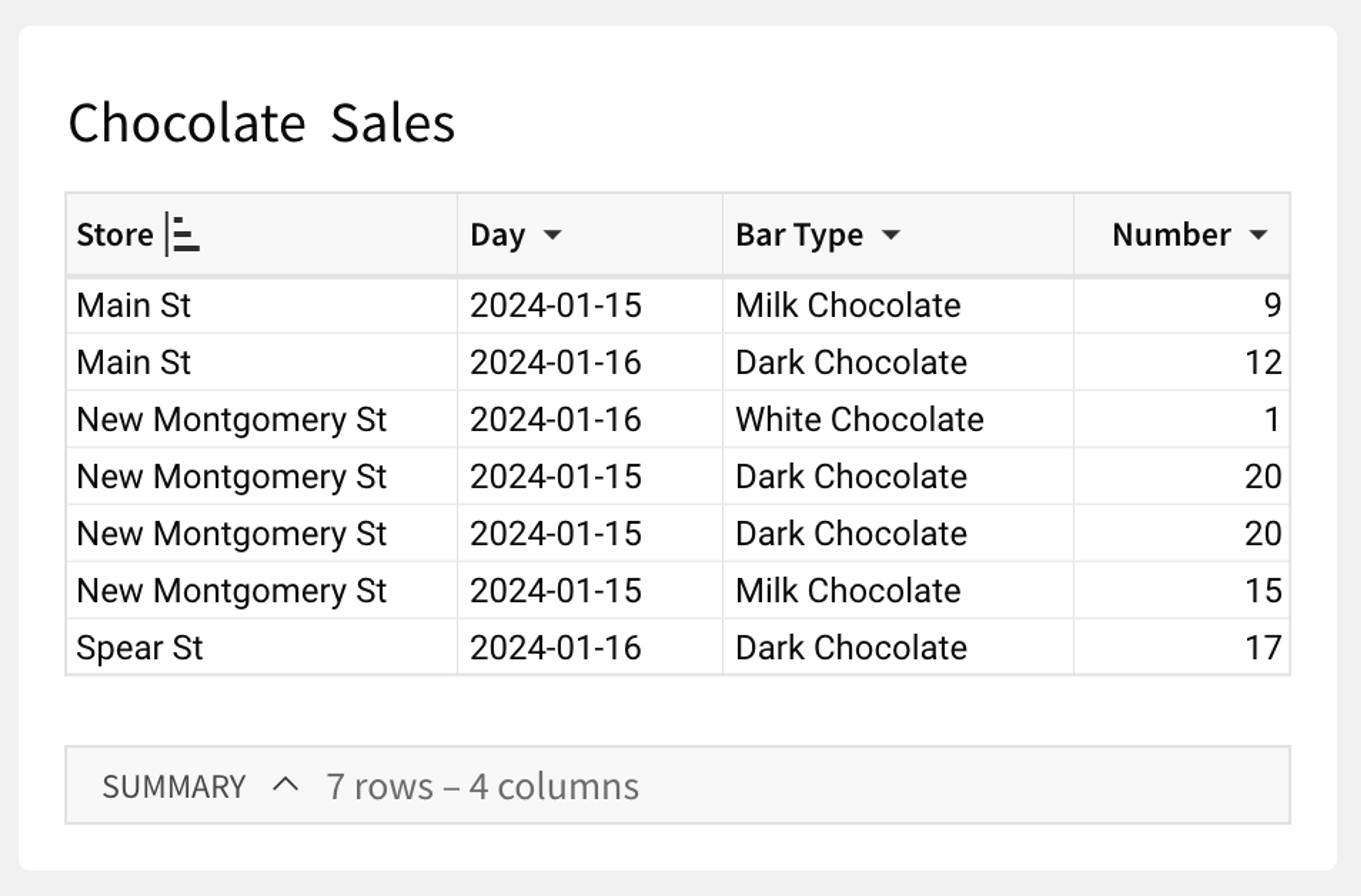
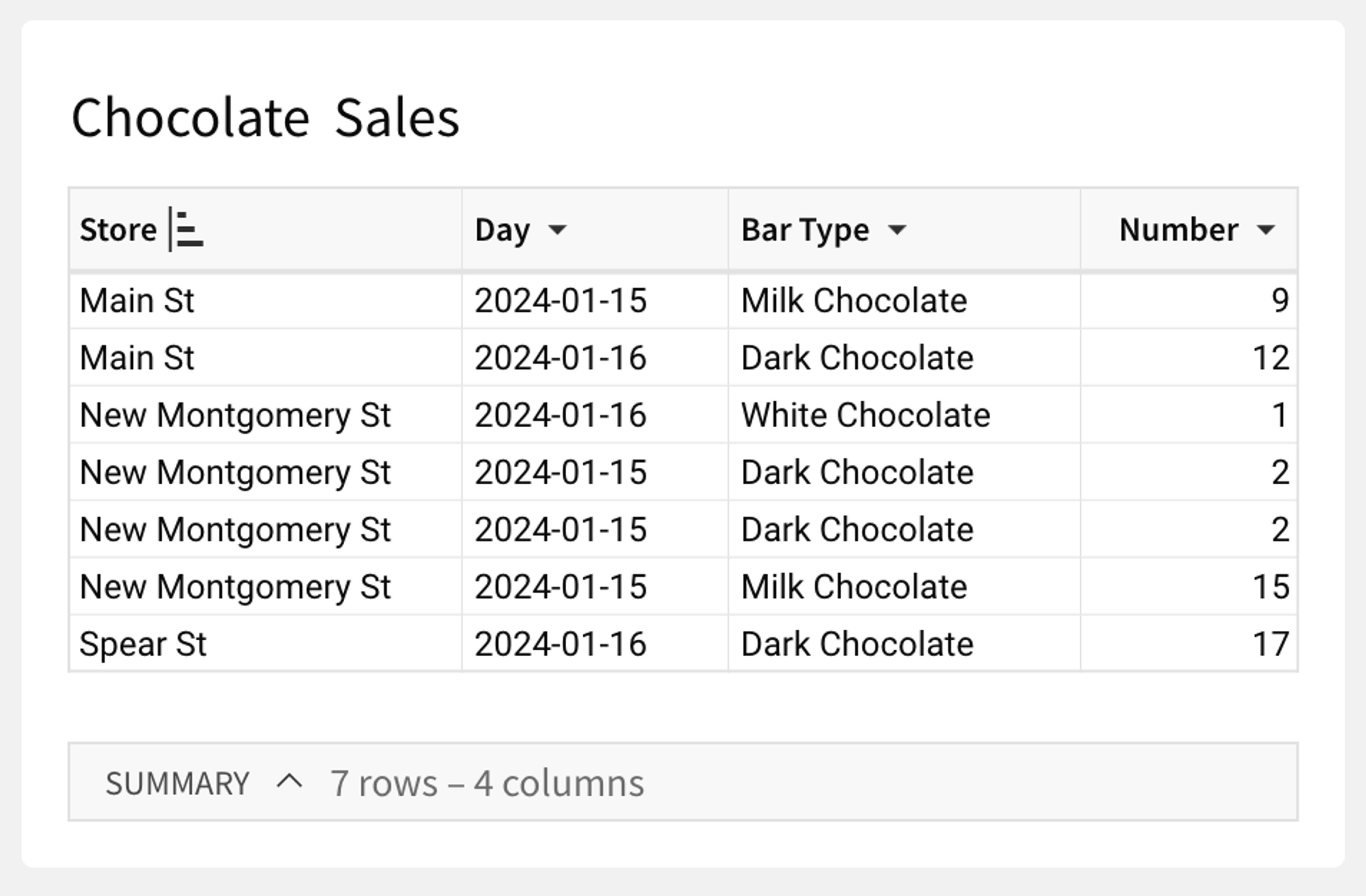
If you want to update a row, you have to identify the row based on the data it contains (and if multiple rows have the same identifier, you'll end up updating all of them).
A spreadsheet, on the other hand, gives you a fixed grid of cells that act as containers for data: if you put some data into cell A1, that data will stay in A1 until you put different data into A1. Every row has an explicit row number, so you always know which row is which and what order the rows are rendered in. You can update a particular row even if it has the same data as a different row.
Translating
The SQL model is kind of like slicing a spreadsheet into separate rows, cutting the row numbers off, and then dumping the rows into a bag. When Sigma's SQL queries pull rows back out of the bag, we have no idea where they should be in the spreadsheet unless we put that information directly into the row data.
Since the table's data isn't guaranteed to have a column that we can sort on, we need to provide an extra column for each row to determine the sort order. In a spreadsheet, this is an integer (the row number), but for input tables, we use a fractional index so that we can add new rows and move rows around without updating the sort value for other rows.
Strictly speaking, a unique row order column is all we need. But to make our lives easier, we also add a unique identifier to each row (we use a random UUID). Since users can move rows around, it's easier for us to refer to a row by its unique ID rather than by its row order.
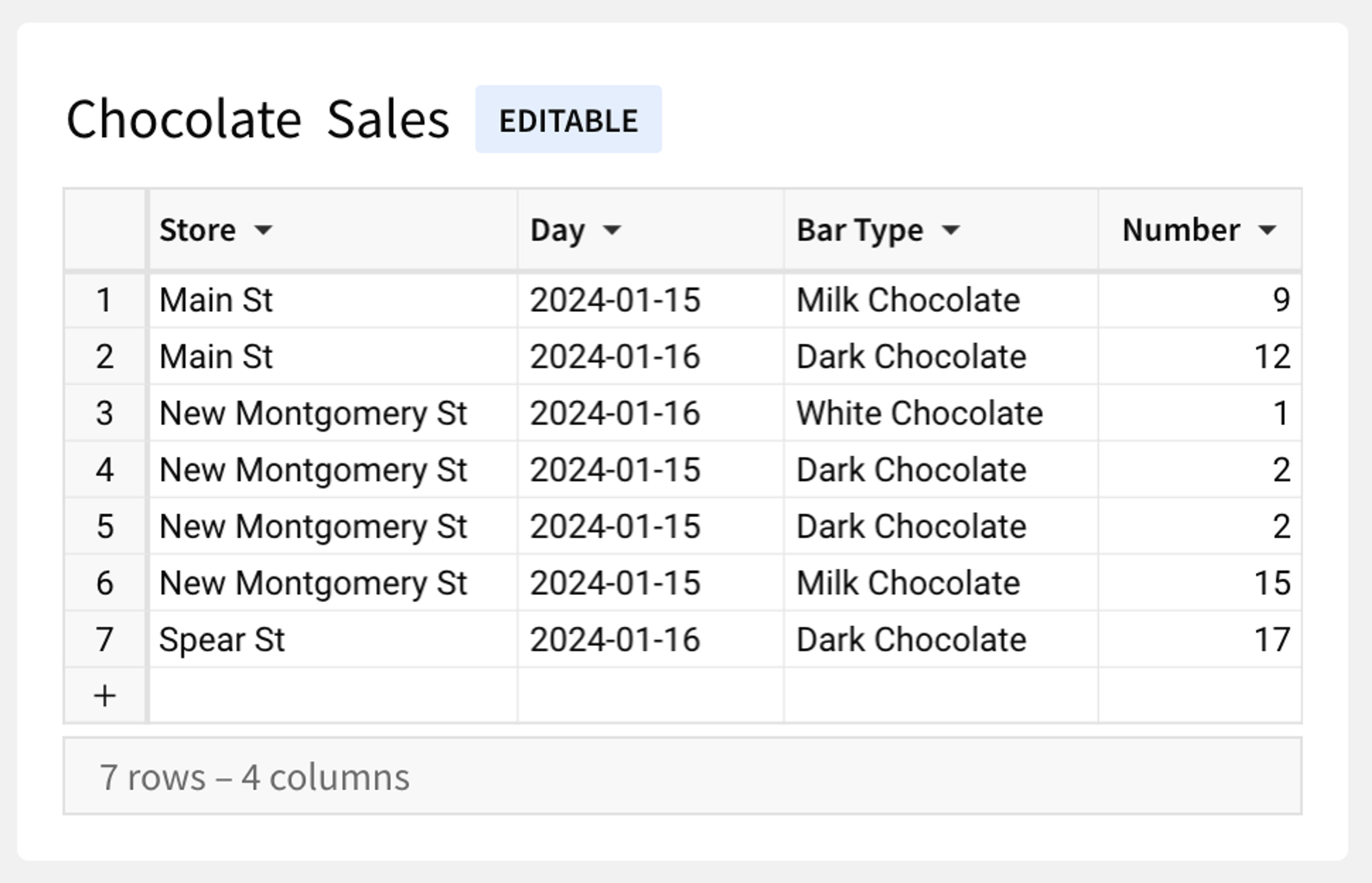
Here's the same Chocolate Sales table as above, but this time as an input table:
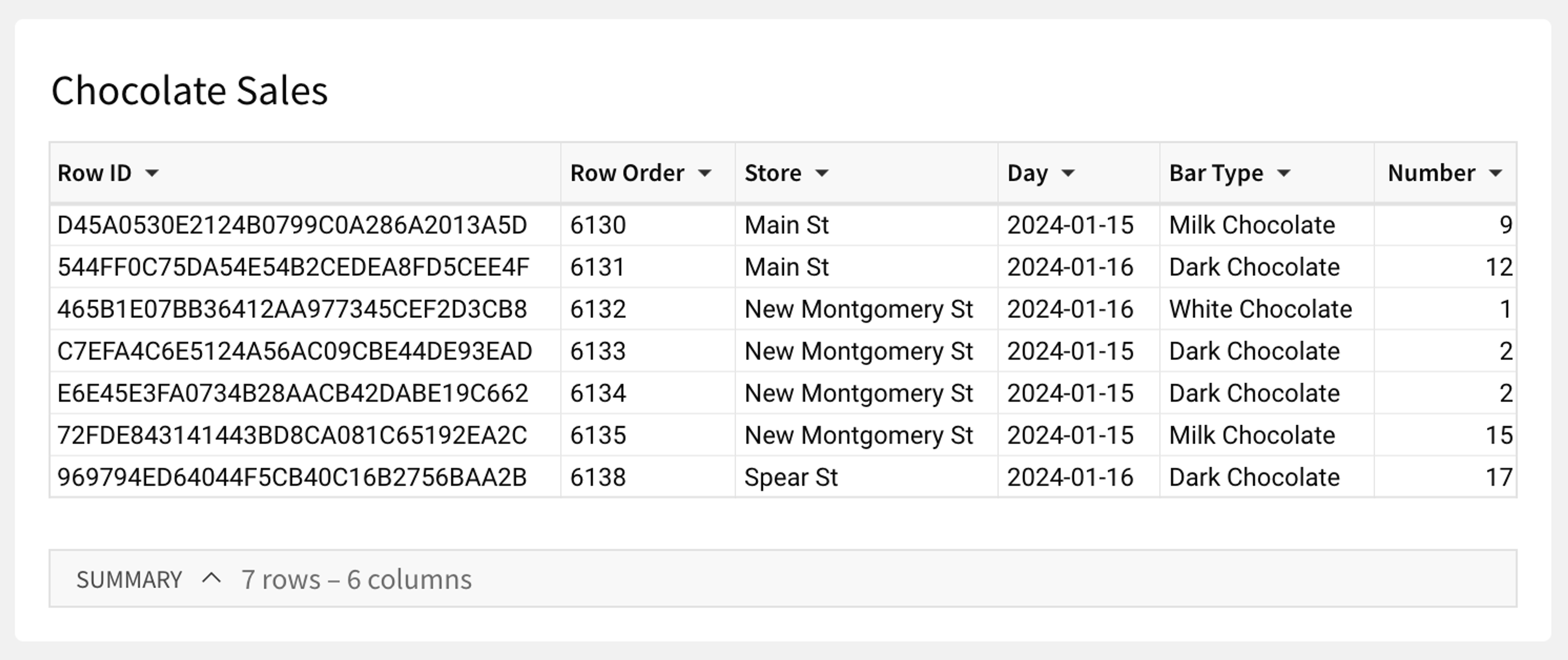
You can see that the input table is ordered by the row order column, and each row has a unique ID. With these columns, we can guarantee that the input table's rows have a stable order and that we always know which row to update whenever you make changes to the input table.
Conclusion
Input tables let you enter data into your data warehouse by typing values into a spreadsheet. To make this work, we need to express the structure of a spreadsheet's grid of cells in SQL's "bag of rows" data model. We do this by tagging each row with a unique ID (so that we can always pick that row out of the table regardless of the data it contains) and a fractional index (so that we can sort the rows in a stable order).
In the next post in this series, we'll talk about how we made writing to input tables as fast as writing to a spreadsheet, even though writing small amounts of data to an SQL warehouse is slow.
Footnotes
1. Strictly speaking our SQL dialect will probably allow us to group by all of our columns and select the first row in our UPDATE statement, but a) that's complicated, expensive, and annoying and b) the point is that SQL doesn't allow us to refer to a single row except as a function of the data the row contains.
2. In this example it happens to look like a regular old integer, but that's just a coincidental result of the fractional index algorithm we're using. If you were to add a new row between the rows with Row Order 6130 and 6131, the new row would have a row order between 6130 and 6131.