ETL vs. ELT: How Do They Differ &Which Should Your Company Use?
Are you considering a move to a modern cloud data warehouse like Snowflake, BigQuery, or Redshift? If so, you’ve probably got a few questions about building the right data pipeline. Which route should you go (build or buy), and how do you get data from point A to point B (ETL vs. ELT)?
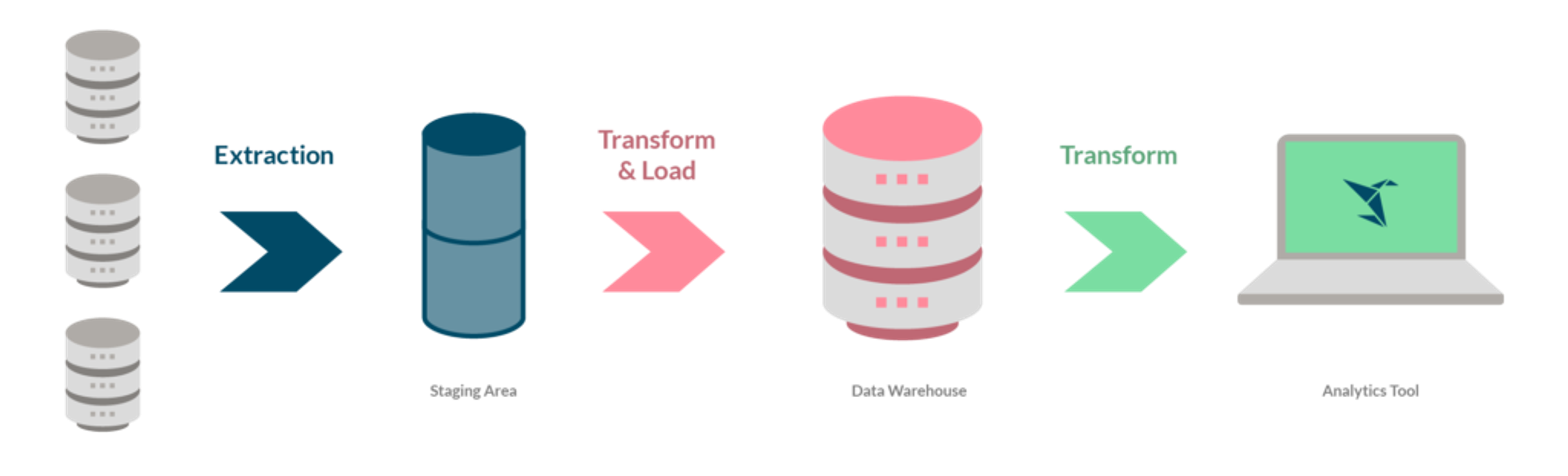
Manually extracting data from your systems and applications to the warehouse isn’t easy. But ELT and ETL solutions can help. They help replicate data to the cloud warehouse for analysis. This centralized data store gives you a fuller picture of what’s happening across the company and eliminates any data silos that may exist along the way. You can capture data from your applications, e-commerce events, other databases, and more.
But which method is right for your company, ETL or ELT? What’s the difference between the two? And perhaps most importantly, is there an advantage to one over the other? Read on to learn what each entails, compare ETL vs. ELT, and determine what really matters when choosing a modern solution to build your data pipeline.
What is ETL (Extract, Transform, Load)?
ETL stands for Extract, Transform, and Load, and is the traditional process of moving data from original sources to a data lake or database for storage, or a data warehouse where it can be analyzed.
The ETL Process
In the past, this usually involved moving data from one database to the warehouse. But this has quickly changed over the last decade as companies began to rely more on third-party SaaS applications that produce multiple streams of data. Examples include Salesforce, Workday, Marketo, and Zendesk. These platforms communicate via APIs with an ETL tool to constantly transfer live data from point A to point B, commonly referred to as the “data pipeline.”
- Extract: retrieve data from sources
- Transform: compute and format data for integration
- Load: transfer data to the data warehouse, database, or data store.
ETL solutions are no stranger to the data stack. However, the rise of SaaS apps require modern enterprises to manage huge amounts of structured and unstructured data in real time from multiple sources at a massive scale—something legacy ETL vendors and on-prem data warehouses can’t manage. When selecting an ETL vendor, be sure it supports your SaaS toolset and transfer needs.
What is ELT (Extract, Load, Transform)?
ELT stands for Extract, Load, Transform, and (Extract, Load, Transform) is a modified pipeline that loads the extracted data into the cloud data warehouse where transformation occurs.
The ELT Process
This process can be advantageous as it allows you to leverage the power of the cloud to perform complex joins and calculations.
Taking a parallel approach means that you can perform transformations where it makes the most sense for your workflow—in the pipeline or the warehouse. This method is becoming more common as companies seek to avoid the risks of poorly performing hardware and the costs associated with upgrading an existing ETL infrastructure.
What’s the Difference Between ETL and ELT?
The real difference for business all boils down to time, cost, and performance.
Time
The ETL method takes significantly longer to transfer and load data into the warehouse. Why? ETL solutions generally have a staging area where the data must enter first to transform. Transformation time depends on the size of the data set, meaning larger sets can take hours.
Cost & Resources
Maintenance can also add time to the process, and eat up costs. After all, someone has to maintain that infrastructure. If you have a large data team to manage your infrastructure internally, this may not be an issue. But be aware of the upfront and ongoing investments you will need to make.
Fully managed ELT solutions benefit from a single system that leans on the cloud to do the heavy lifting. Meanwhile, seamless data connectors from companies like Fivetran, ensure your data is up to date without constantly updating the infrastructure.
This method is particularly beneficial for companies that don’t have—or want—to spend the resources and costs maintaining a data infrastructure. Additionally, by flipping the model on its head, you eliminate the need for analysts to know what they want to analyze before transformation occurs. Instead, you get a replicated warehouse that makes it possible to transform data on the fly.
ETL vs. ELT
Learn about ETL and ELT so you can decide which method works for you.
What to Consider When Comparing ETL vs. ELT Tools
Here are our top considerations as you explore ELT and ETL solutions for your company:
Flexibility
Choose a vendor that manages multiple data sources, including support for structured and unstructured data—even if you don’t need that support today. This may come into play down the road, and if it does, you won’t need to change providers.
Cloud Data Warehouse Support
Not all ETL/ELT vendors are created equal. As mentioned, modern pipeline solutions integrate with cloud data warehouses, whereas legacy ETL tools only integrate with on-prem data warehouses. Be sure the vendor works well with your data warehouse of choice.
Pricing
While each ETL/ELT vendor prices their solution slightly differently, it’s important to have a basic understanding of pricing frameworks. You’ll want to take the pricing mechanisms into consideration to ensure the price works for your company now and in the future, should you integrate additional data sources or scale significantly. The last thing you want is to invest in a vendor and find out that a year later, it’s no longer a feasible option. Switching costs can add significant time investment and cost downstream. Planning upfront can save you headaches in the long run.
Today’s vendors tend to charge on a monthly recurring pricing structure; you may also encounter annual pricing as well. Here’s a breakdown of some of the most common pricing mechanisms for ETL/ELT providers:
- Integration-based Pricing:
Some vendors have various levels of pricing based on the number of data source integrations you work with. It’s not uncommon to see multiple tiers that range from 2, 5, 10, or unlimited integrations with data sources. - Row-based Pricing:
Another common pricing mechanism that you may come across is a row-based approach. For example, one pricing tier will cover up to 25M rows of data, while another 50M or 100M, and an enterprise level may be custom priced, but support unlimited rows of data. - Volume-based Pricing:
While not as common as the other pricing mechanisms covered above, some vendors may charge based on the volume of data pushed through the pipeline per month—measured in the maximum transmission unit, or MTU.


