How Sigma streams query results with Arrow and gRPC

Context
Customers love using Sigma because it provides them with direct access to all their data in different Cloud Data Warehouses (CDWs), a sweet spot between basic, raw SQL access, and dashboards maintained by a dedicated team. With Sigma, you can explore your data, at scale, derive useful insights quickly, and get back to work.
While this works well, we want to support a lot more organizations, each with a lot more users, and allow all of them to explore a lot more data, while making fewer round-trips to the customer’s CDW.
We were limited in our ability to handle this scale:
- The result from the CDW is built up into a large payload that has to be sent over the wire
- Any transformation applied to the result required first deserializing it, applying a change, and then re-serializing it
- We have to deserialize this blob again at the browser, before populating its in-memory representation
- We were seeing high memory consumption, frequent instances of services being killed by going out-of-memory, and latency due to serialization/deserialization.
We needed to change the way our services talk to each other, and the way we represent and manipulate this data.
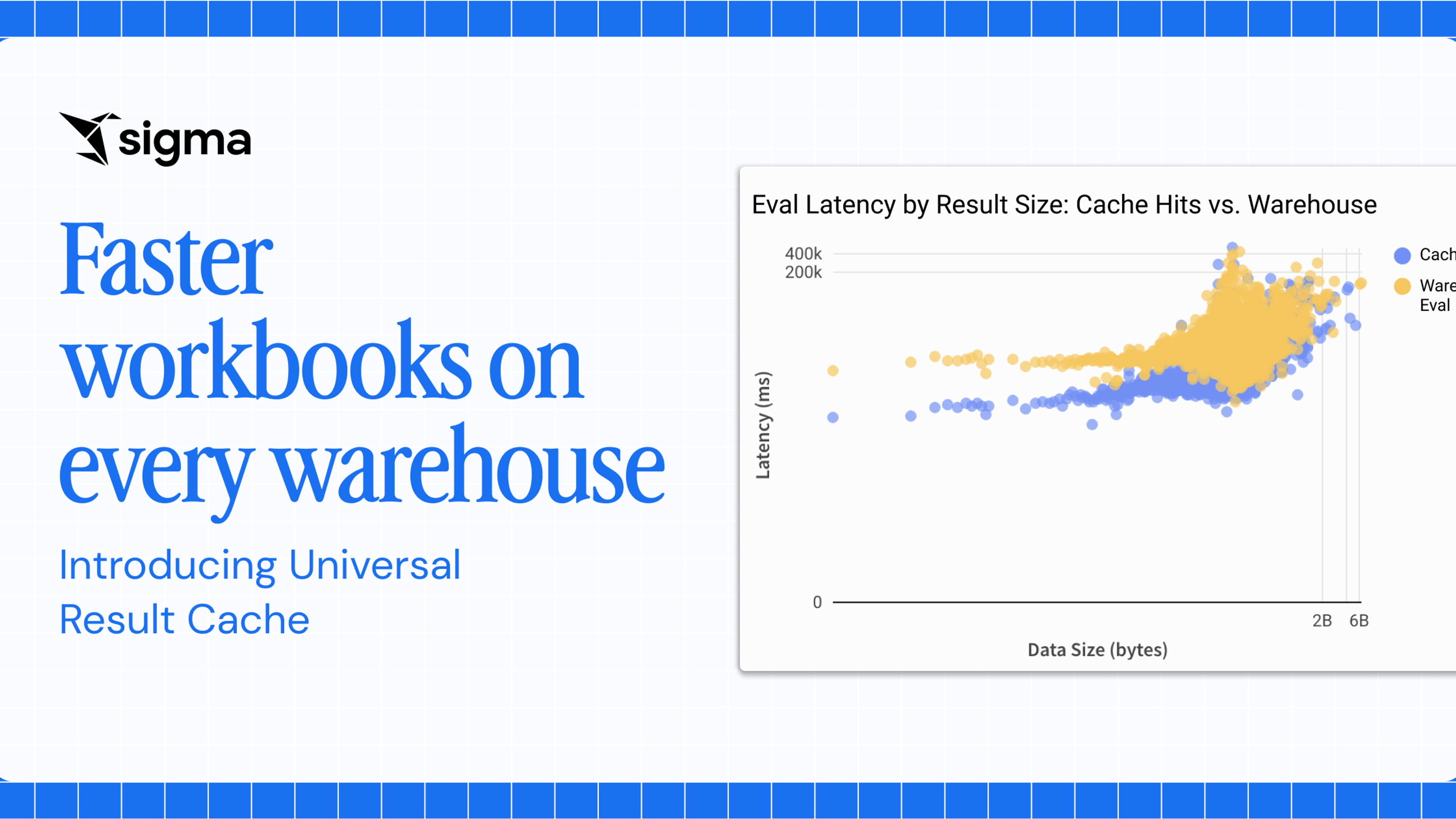
Compared to a few months ago, we now move 3x as much data, from the warehouse to the browser. We use 5x less memory while applying transformations to this data. At the same time, we have reduced latency from the browser to the warehouse by 33%, and reduced latency within the browser by 50%.
Read on to find out how!
The life of a query
Customers create Workbooks within Sigma, which provide a spreadsheet-like interface on top of their data in their CDW. Within a Workbook, they can explore one or more tables, easily derive multiple visualizations, and create dashboards. These can be collaborated on, and shared with, other users within the same organization.
All forms of user interaction within the Sigma application may generate queries on behalf of the customer to their CDW. As shown in this brief clip, users can see the SQL corresponding to these queries by clicking and bringing up the “query drawer”.
Some queries are fulfilled by transformations in the browser, and some go all the way to being executed within the CDW (i.e. as of today, one of Snowflake, Redshift, Bigquery or a Postgres instance, with Databricks coming soon).
Here we focus on Workbook interactions that result in evaluation requests (“evals”) that require execution within the CDW.
Query flow
Here is a (oversimplified) block diagram of the overall flow.

- Through our Compiler service, we figure out the precise SQL for the query.
- This gets forwarded to a CDW interaction service, which is responsible for queuing up queries
- This interacts with the CDW and, using the appropriate driver, fetches the result of running the SQL within the CDW.
- These results may be simply passed through, but might also need to be transformed to account for how the frontend needs to present the results.
Arrow
Arrow, an Apache project, had some appealing characteristics for us:
- A columnar memory format
- Multi-language support
- Supports zero-copy reads
- It has won sufficient mindshare to be considered a standard format: today, both Snowflake and Bigquery support delivering results in Arrow instead of JSON.
To illustrate the difference, here is a portion of a JSON response and the equivalent Arrow response (omitting aspects like (1) optional multi-valued cells, (2) optional repeat-counts for grouped data, (3) levels of data, as well as (4) other metadata).
Each response corresponds to the simple case of a single table with two columns, “food items” and “quantities”.
- Within the JSON version of the response, we have a hierarchical structure of key-value maps
- Within the Arrow version of the response, we have each column represented as a contiguous vector in memory, so that the response itself is (1) a schema describing which types are present, and (2) a list of these vectors.


Every service-response in the diagram of the query-flow we mentioned earlier, is a JSON payload. Each row in the result is represented as a separate entry in a JSON map. Every data-type must be represented as a string, and converted to-and-from its string representation. This takes up space, a lot of space.
A columnar-layout is preferable because
- it matches how we interact with the result-data, “a column at a time”, filtering out entire columns, applying transformations to all elements of a column, etc
- it’s more space-efficient, packing together all elements of a certain data-type, allows for cache-efficiency (and when needed, vectorized optimizations)
- It can often preserve the binary-encoding of the result (without the intermediate serialization/deserialization) all the way from the CDW back to the browser, delaying the unpacking into individual cells.
Also, we had already transitioned our browser app to use Arrow internally (i.e. it converted the JSON it received into columnar Arrow format and then used this to render the state of graphs and tables). Extending this across the rest of our stack, both in the way data is stored and manipulated, and in the way data is sent and received, allows us to preserve, as much as possible, the same bits received from the CDW after executing a query, show up at the browser!
Further optimizations
gRPC
An initial prototype of this change showed improvements in browser latency, but it was hampered by the need to encode/decode the binary payload within the JSON payloads that our services sent across REST interfaces.
At the same time, we also wanted to be able to allow for responses to be streamed, in order to support larger responses, without suffering from spiky memory usage.
So, in parallel with the change to the form of the payload, we transitioned (service by service, sometimes endpoint by endpoint) our services over to use gRPC.
Streaming/chunking
This has the added benefit of having a well-defined protobuf “schema” for each service boundary, which can have its own repository and be version-controlled.
I had mentioned earlier how Bigquery and Snowflake support retrieving results in Arrow; we can group some number of rows into a chunk.
So, in the ideal case, for eval queries, a given chunk (still in columnar form) can therefore move unchanged all the way from the customer’s CDW to the browser.
In some cases we need to process the data on its way to the browser. Streaming allows us to do this in chunks, instead of deserializing the entire blob, processing, then re-serializing and sending out. This saves a lot of memory and processing power.
Here is a diagram showing the same services as above, annotating request/response paths with the transport used:

We looked at a few things to measure the impact of these changes
- Data transferred back from the CDW
- Browser latency
- Resource usage of our backend services
- End-to-end time, excluding time spent executing the query at the CDW
See below for graphs showing each of these metrics. The period of time in these graphs that shows the changes being fully implemented is the month of March.
Reduction in memory usage
- This graph shows the total memory usage by all instances of a service that performs transformation/post-processing on data returned from the CDW
- This total memory usage is about 5x less than it was earlier
- We used to have “spiky” memory usage, which frequently resulted in Out-Of-Memory crashes. Now, however, we have a low, and stable memory usage.

- These graphs show the P90 latency (milliseconds) of a request originating from the browser, after subtracting out the time taken for executing within the CDW. Note: this is a measure of “Sigma overhead”. It is the amount of time, from the user’s perspective, that is attributed to Sigma. This is the part of the query-flow that we control, and is one part we try to minimize.
- The first graph shows a week, from a few months ago, when the evaluation queries were using the older path, and the second graph shows a recent week, using the newer path
- The first graph has large spikes and is generally higher. The overall baseline latency has reduced by about a third of what it was earlier.


- This graph shows the (P95, in milliseconds) time taken at the browser to transform the result received, and compares requests (originating at the browser) that use the older path or the newer gRPC/arrow/streaming path
- The latency of this step is 50% less with the new pipeline.

Overall, our backend services are more reliable now (we used to suffer from a lot of OOMs and crashes that do not occur any more), and we serve a larger amount of data more efficiently than we used to.
The improvements we have made gives us the confidence to on-board more customers, and larger organizations.
As we continue to grow, we encounter a lot of interesting engineering challenges, and we will continue to write about our experiences with analyzing and improving our product. Come join us if you’d like to help!