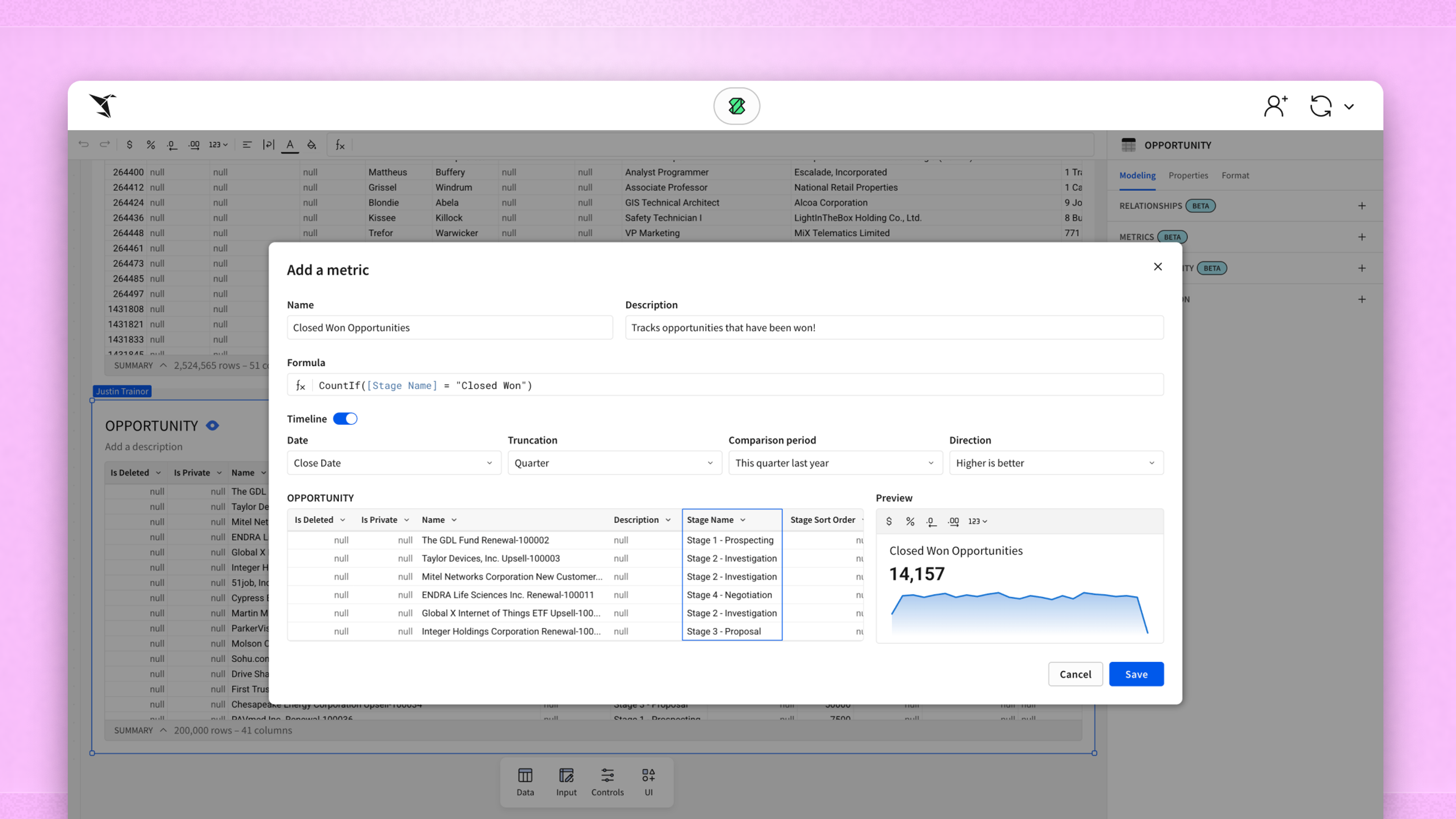
Data Debt: The Silent Killer Of Scalability

Your dashboards have multiplied, and so have your data tools. But getting to a single version of the truth still feels out of reach. Every new request pulls your team into another one-off report, another stale spreadsheet, and another chase for the right number. That marketing report your team spent weeks building? It's probably wrong. Not because your analysts messed up, but because somewhere along the line, someone made a "temporary" fix that became permanent. You’ve hired smart analysts and invested in modern tools. So why does it still feel like the data is working against you?
This is data debt, the hidden cost of all those quick solutions and undocumented workarounds that accumulate in every growing organization. Unlike technical debt (which at least gets discussed in engineering standups), data debt grows silently until suddenly:
- Your "monthly" reports take weeks to produce
- Different departments show conflicting numbers for the same metric
- New hires spend months untangling spaghetti-lineage dashboards
We'll show you how to spot data debt before it derails your growth plans, and how forward-thinking teams are tackling it headfirst.
Here’s the part most leaders don’t see coming: the problem isn’t your team. It’s not your stack. It’s the hidden mess that’s been building underneath it all quietly, incrementally, and out of sight. And like any kind of debt, the longer it’s left unaddressed, the more it costs you.
Why data debt matters now
Over the past few years, your data stack has expanded to include more dashboards, self-serve tools, and pipelines running in the background. But with that growth comes confusion. The number of tools and what happens between them are all impacted. Metrics drift, and definitions shift. Teams move fast, and so does the data. Before long, no one’s sure what’s current, accurate, or who owns what. When you add in AI tools that pull from half-clean sources, the problem snowballs.
Executives want faster answers, and boards want proof of return on investment (ROI). But your team is stuck reconciling numbers that don’t match or rebuilding what broke last quarter. What you’re seeing is more than growing pains. It’s the cost of decisions made on the fly, compounding over time. And it’s why data debt is rising faster than most leaders realize.
What exactly is data debt?
Data debt is the accumulation of decisions that prioritize speed over structure through quick fixes, one-off solutions, and undocumented workarounds that quietly pile up across your systems. It doesn’t come from one bad choice. It builds over time. A dashboard gets cloned and edited without changing the title, a column gets renamed without telling the downstream users, or a pipeline breaks and is patched, not rebuilt. Multiply that by years, teams, and tools, and suddenly, your clean data strategy is cluttered with invisible liabilities.
Here’s how it creeps in:
- The quick fix: An analyst hardcodes values to hit a deadline. The report works for now, but it breaks three months later when the assumptions change.
- The black box: A critical ETL job runs nightly, but no one knows exactly how it works, and the one person who did left the company.
- The spreadsheet monster: That “temporary” Excel file now feeds 12 dashboards, none of which agree.
- The orphaned asset: Reports no one uses, but everyone’s afraid to delete, just in case someone still relies on them.
The impact isn’t limited to analysts. Product teams feel it when they’re stuck piecing together manual data pulls, finance encounters issues when numbers don’t align across reports, and executive leadership faces it head-on when decisions are being made from conflicting metrics.
Data debt doesn’t always announce itself, but its effects show up quickly. Trust erodes, delivery slows, and confusion builds. By the time it surfaces in reports or is called out in a meeting, it’s already deeply rooted in the systems behind the scenes.
7 signs your team is carrying data debt
- Your analysts are stuck in cleanup mode. Most requests turn into a scavenger hunt: fix the filters, merge the mismatched sources, figure out why the numbers don’t match. By the time the actual analysis starts, the deadline’s already looming.
- No one agrees on the numbers. Finance has one revenue figure, marketing has another, and product has three versions of the same metric. Meetings turn into reconciliation theater, where time is spent debating which numbers are “right” instead of what they mean.
- You’ve got reports no one wants to touch. We all have that one dashboard that was built by someone who left, runs on fragile logic, and is too complicated to rebuild. So it just sits there, half-accurate and fully untouchable.
- Tribal knowledge is holding everything together.
If someone asks how a report works, the answer usually starts with, “Talk to Sarah.” When your best analysts become the institutional memory, continuity depends on who’s still around. - Business teams are spinning up their own data.
Shadow systems, such as spreadsheets, one-off tools, and side-channel exports, emerge when official reports can’t be trusted or fail to deliver what teams need. It fragments trust and creates duplication you can’t see. - Onboarding new analysts takes too long.
When documentation is sparse and naming conventions are inconsistent, new team members spend their first few months chasing definitions and Slack threads instead of focusing on meaningful work. - You’re always firefighting.
Your data team is in reaction mode, patching broken dashboards, backfilling bad data, and answering urgent questions instead of planning. The backlog continues to grow, and trust continues to shrink.
Quick diagnostic: How many dashboards would break if one key person left tomorrow? If that number makes you uncomfortable, it’s a sign that data debt has already started to spread.
How data debt spreads
Data debt builds quietly, through well-meaning decisions made under pressure, until it becomes a pattern. What starts as a quick fix slowly shifts how teams work, how tools interact, and how decisions are made.
Here’s how it takes hold and why it becomes so difficult to unwind:
| How it takes hold | What it looks like | Why it’s dangerous |
|---|---|---|
| It starts with small exceptions | A spreadsheet gets pulled for a one-off request. A column is renamed to patch a bug. A report is rebuilt from scratch because no one trusts the original. Each of these choices feels harmless in the moment. | Small exceptions accumulate quietly. Over time, they introduce inconsistencies that aren’t flagged until reports contradict each other, or decisions get second-guessed. |
| Workarounds become the default | Teams duplicate dashboards instead of updating shared sources. Data is exported to sidestep delays. Quick fixes spread from one workflow to the next. | When workarounds replace processes, teams lose alignment. Metric definitions diverge, effort gets duplicated, and no one’s sure what’s accurate. |
| Speed outruns structure | Everyone’s moving fast, and documenting decisions takes a back seat. Debt spreads from constant urgency, not carelessness. | Without process or pause, fragile systems grow unchecked. Issues stay hidden until they become blockers, often during high-stakes moments. |
| Systems grow harder to explain | Reports tie into legacy tools no one owns. Definitions shift. Overlapping platforms create noise instead of clarity. | As logic disappears and ownership fades, teams grow hesitant to make changes. Innovation slows, trust drops, and maintenance becomes a liability. |
| Leaders discover it too late | The pattern isn’t visible until something breaks: a dashboard goes down, a number can’t be explained, or a project stalls. | By the time leadership sees the issue, the damage has already spread. Teams default to firefighting mode, and long-term strategy takes a backseat. |
The ripple effects of data debt
Data debt slows down your analysts, seeping into how the entire organization makes decisions. When no one’s sure which number to trust, conversations stall. Meetings shift from planning what’s next to debating what’s true. While teams try to move forward, they’re constantly second-guessing the data beneath them. As the backlog grows, analysts stop asking proactive questions and start reacting to whatever broke last. Instead of iterating on insights, they’re cleaning, reconciling, and explaining over and over.
Eventually, trust takes a hit to the dashboards, process, team, and sometimes the very idea that data can help at all. People start pulling their own numbers, spinning up shadow systems, or skipping the data entirely. And when that happens, leadership loses visibility. You’re no longer looking at a shared view of the business. You’re looking at fragments, each shaped by different definitions, time frames, and assumptions.
That’s the real cost. It’s the slow erosion of confidence. In the data, the team, and the decisions being made.
How to measure your data debt
You won’t find a single dashboard that says, “Here’s how much data debt you’ve got.” But there are ways to start sizing it up and spotting where it hits hardest.
There is no dashboard that flashes a warning when data debt reaches a critical level. It doesn’t show up as a single metric or alert. But that doesn’t mean it’s invisible. If you know what to look for, there are clear indicators that your team is carrying more debt than you think. They appear in your workflows, among your people, and influence your decision-making speed.
Here’s how to start measuring where it’s showing up and how deeply it's impacting you.
Start with time
How much of your analysts’ week is spent preparing data versus analyzing it? If you don’t have a hard number, estimate it throughout a sprint. Are they chasing down broken joins, rewriting filters, and merging mismatched tables? If prep work consistently pushes the actual analysis to the back half of every project or gets dropped entirely, that’s not just inefficiency. That’s interest on your data debt.
Over time, this compounds. What looks like “just how things work” is often a backlog of Band-Aids masking a deeper issue.
Look at repetition
Are the same types of reports being recreated across different teams? Are people pulling custom versions of dashboards because they don’t trust the existing ones or can’t find what they need? That’s duplication, and it’s expensive in analyst hours and strategic misalignment. If marketing, finance, and product are each defining the same metric slightly differently, you’re no longer working from a shared understanding of performance. Repeated work is rarely about laziness. It’s usually a sign that the original solution didn’t stick or didn’t scale.
Review your documentation trail
Grab a few reports at random and see if you can answer basic questions about each one. Where did the data come from? Who built the logic? When was it last updated? What assumptions were made? If those answers aren’t immediately accessible, or if nobody knows you’re flying blind. And as your team grows or changes, the gaps will only widen. Documentation isn’t about compliance. It’s about continuity.
Examine onboarding
How long does it take new analysts to get productive? If the answer is measured in months, and most of that time is spent learning which reports to trust and who to ask when things break, that’s a signal. A long learning curve may appear to be a hiring issue.
However, it often points to structural debt, such as inconsistent naming, unclear ownership, and legacy dashboards thave not been has touched in years. A smooth onboarding process reflects healthy data practices. A messy one reflects all the shortcuts you haven’t cleaned up.
Ask your team
Not everything shows up in metrics. Sometimes, the clearest indicators come from the people closest to the work. Ask where they feel friction, which reports they avoid, what parts of the stack “just don’t make sense,” and what breaks more often than it should.
These conversations don’t need to be formal, but they should be regular and ongoing. Because if your team is tiptoeing around certain systems or relying on workarounds that never get documented, those are pockets of debt waiting to emerge at the worst possible time.
These provide a baseline and a way to track progress.
How to start reducing data debt
You don’t need a six-month roadmap or a reorg to start cleaning up data debt. What you do need is consistency. Most of the time, the fix isn’t one big initiative; it’s a set of small changes that stick. Start with what’s slowing your team down, then build the habits that prevent debt from recurring.
Fix what’s broken and visible
Before launching anything formal, run a quick audit. Ask your team to flag the three most broken or mistrusted reports. What decisions rely on them? Who still uses them? Do they need to be fixed or retired?
At the same time, create a space where people can raise issues as they find them. This can be a Slack channel or a shared doc. What matters is visibility. Let teams surface their top pain points, then prioritize fixes based on business impact, not technical complexity.
You’ll be surprised how much cleanup starts to happen when you give people a place to talk about what’s slowing them down.
Start with naming, not tooling
Pick one metric that’s used across multiple teams and define it clearly. Then label it the same way everywhere it lives. You don’t need a semantic layer or a metadata catalog to create consistency. You need an agreement. And a consistent name beats a clever one, every time.
Build cleanup into everyday work
Massive data cleanups rarely get finished. They get deprioritized the moment something urgent comes along. Instead, build cleanup into your regular workflow. Archive dashboards that no one uses and deprecate legacy reports. When you touch a dataset, ask whether it still needs to exist or if it’s just been hanging around because no one wants to be the one to delete it.
If you manage sprint cycles, reserve a slice of each cycle, maybe 10–20% for debt reduction.
Assign ownership, not just access
Every report, dashboard, or dataset should have a name attached to it to create clarity. Ownership means that someone can answer questions, changes aren't made in the dark, and when something breaks, your team knows who to contact instead of guessing or rebuilding from scratch. When no one owns the data, no one trusts it.
Make documentation part of delivery
Documentation doesn’t need to be perfect, but it needs to exist, and it should live where people work. When your team ships a dashboard, include a brief note on how the metrics were calculated. If they’re building a model, surface the logic somewhere visible, not buried in a notebook or lost in a Slack thread. Documentation shouldn’t be treated like extra credit; it’s part of the product.
Talk about debt in retros
The signs of data debt often appear in the detours from your sprint goals. If you’re already running retrospectives or postmortems, use them to ask what slowed the team down. Was it tracking down the source of a metric, untangling a legacy dashboard, or re-explaining a model no one documented? You don’t need to create new meetings. Just start asking better questions in the ones you already have.
Start small. Stay consistent.
Most data debt doesn’t come from bad decisions; it comes from rushed ones. Reversing it takes time, but the path forward isn’t complicated. It requires clarity, ownership, cleanup, and communication; a little at a time. The teams that stay ahead aren’t the ones who clean house once a year; they're the ones who continually tidy up.
These aren’t silver bullets, but they chip away at the clutter. And the more you normalize these habits, the less debt your team takes on without realizing it.
How modern platforms help data debt
The right platform can’t fix bad habits, but it can make better ones easier to maintain. When your data lives in one place with access that’s tracked and logic that’s visible, teams stop building in isolation. People can find what exists, understand how it works, and know who to ask when something breaks. Modern tools help highlight what’s fragile. Version history, schema checks, and alerts when things break aren’t just features. They’re guardrails that help your team spot problems before they snowball.
They also make documentation less of a chore. When logic, definitions, and data lineage live alongside the work, it’s easier to keep everything aligned. Good platforms don’t solve data debt, but they give you a better shot at catching it before it spreads.
Treat data debt like the liability it is
Every organization builds up some form of data debt. It’s part of growing fast, shipping quickly, and trying to keep up with demand. However, when that debt goes unchecked, it creates additional work, slows your momentum, and clouds your decisions.
This is a leadership call. Because the teams that succeed at scale aren’t the ones with the most dashboards or the newest tools, they’re the ones who’ve made data health part of how they operate. That starts with recognizing the signs, asking better questions, and choosing to address the things that are easy to ignore until they become unmanageable.