00
DAYS
00
HRS
00
MIN
00
SEC
WORKFLOW · SIGMA'S FIRST USER CONFERENCE · March 5
SEE THE SESSIONS




Sigma translates spreadsheet operations into SQL on the fly. Switch statements become CASE logic, moving averages become window functions, and pivots compile to your warehouse's dialect.
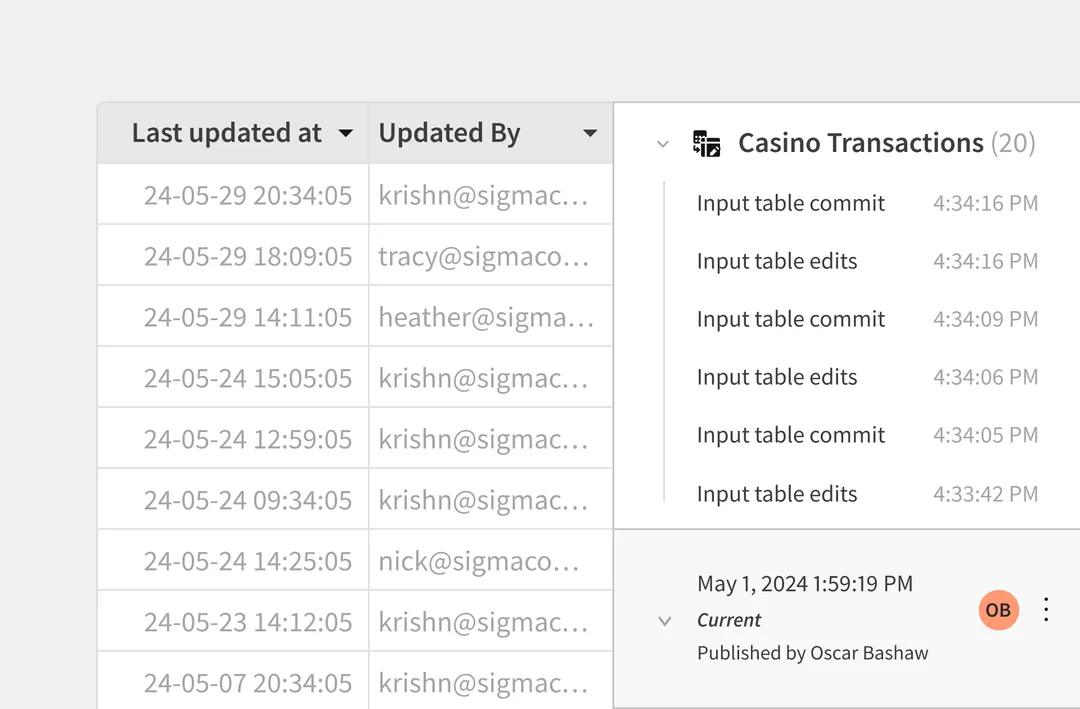
Query History shows the generated SQL for every element, with timing breakdowns and request IDs for warehouse tuning.
Sigma exposes query behavior including queue time, Sigma runtime, warehouse runtime, and result fetch time, plus admin usage dashboards and audit logs.
Built-in templates include cost/performance reporting down to useful cut lines like workbook, query, and user.
Sigma can run as the user (OAuth) or as a service account, and optionally map users/teams to warehouse roles so your warehouse policies are enforced at query time.
You can also define access rules in Sigma to control access to content, data, and features.
Not every interaction should become a warehouse query. Sigma evaluates execution paths:



%201.svg)








The questions that usually come up once someone starts mapping Sigma into their warehouse and governance model.
No. Some interactions are satisfied from the browser cache, some are computed in the browser (Alpha Query), some reuse warehouse cached results via query ID, and some run as fresh warehouse queries. You can see the execution path per query in Query History.
Two levers: (1) the query engine (cache tiers + in-browser compute) is designed to avoid unnecessary queries during exploration, and (2) teams materialize expensive/reused logic back into the warehouse so downstream workbooks hit precomputed tables.
Yes. Query History shows the generated SQL, timing breakdown, and request ID so you can troubleshoot with support or tune the warehouse side.
Sigma enforces permissions in two places: your warehouse (via OAuth run-as-user and roles) and directly in Sigma (via row-level security and column-level security). You can map users/teams to warehouse roles using attributes, and optionally run a published workbook with a service account when needed.
If you use private networking, Sigma supports common patterns like AWS PrivateLink, Azure Private Link, and GCP Private Service Connect. Setup is a joint networking exercise (yours + Sigma's), and it's documented step-by-step.
You can control cache duration / TTL, define acceptable staleness for a workbook, and bypass caches when you explicitly need the latest results.




