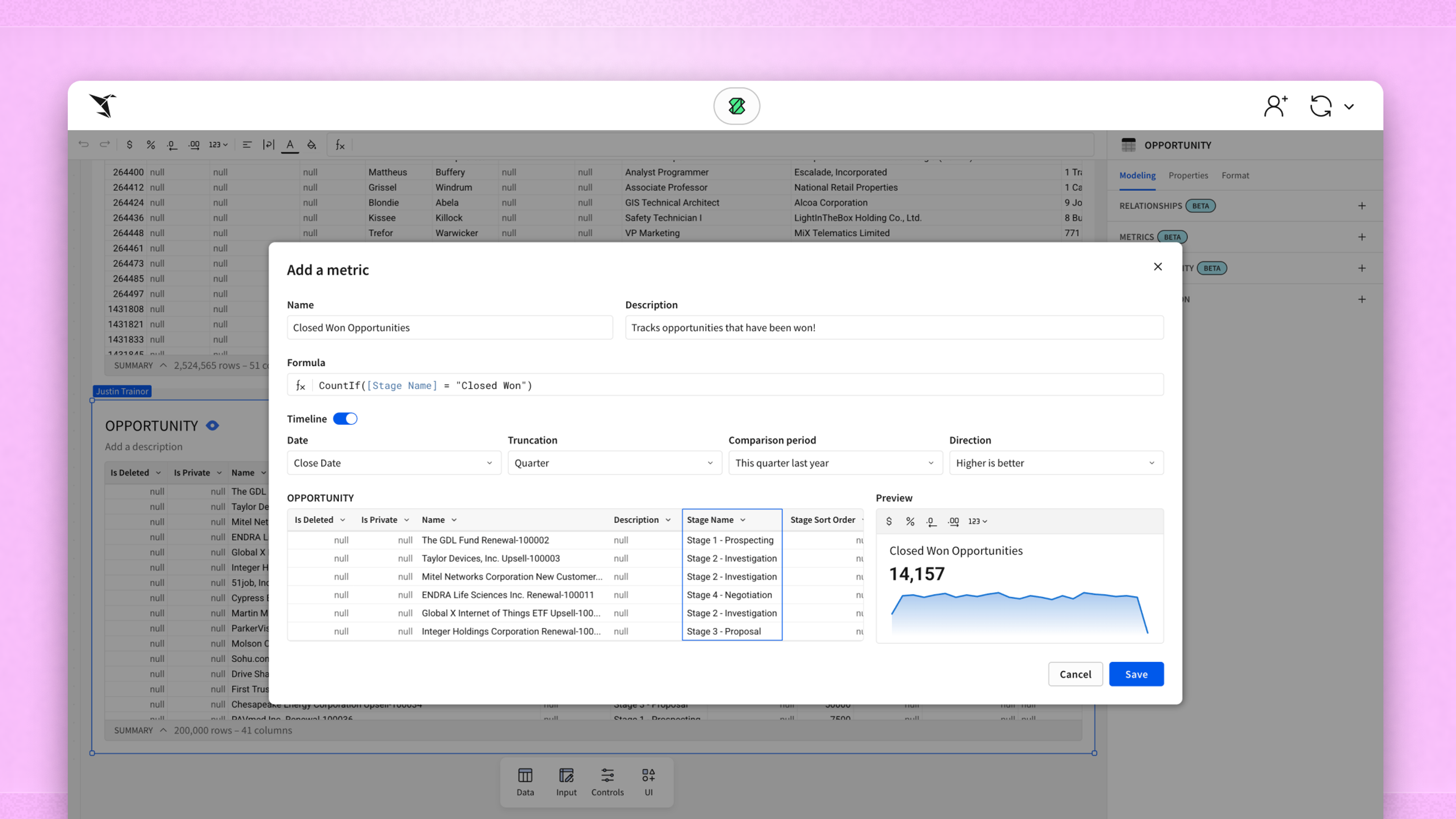
Smarter Text Extraction Techniques Every Analyst Should Know

Text data is everywhere and commonly captured in forms, logs, reports, URLs, and spreadsheets. This type of data often holds insights that structured fields miss, which means that knowing how to extract, clean, and organize text effectively is a game-changer for your analytics team.
Why does text extraction matter in analytics?
Analytics teams and business users are tasked with capturing valuable insights in an environment where the volume and types of data they work with are increasing exponentially. A large subset of this data can be considered structured and easy to work with, but there is a significant portion of data that does not fit this category. This data arrives in messy, semi-structured, or even completely unstructured formats, making traditional analysis challenging. This is where mastering text extraction within a BI platform like Sigma becomes indispensable.
Valuable information often lies hidden within raw or poorly structured text fields. Imagine customer feedback capturing customer sentiment, service logs detailing critical system errors, or product descriptions containing embedded SKUs and features.
In their raw format, these data sets appear chaotic and difficult to work with. These data sets are invaluable and hold the keys to understanding customer pain points, identifying product deficiencies, streamlining operations, and even predicting market trends. These insights require extracting granular details from the messy or chaotic formats to store the data.
Text extraction addresses common business challenges that apply to business units across an organization. Analysts frequently need to pull specific data points like dates from free-form notes, product SKUs from lengthy descriptions, customer names from communication logs, or even tags and codes from system outputs. Efficiently extracting these elements transforms amorphous text into structured data. This data becomes actionable because it can be readily analyzed, filtered, and aggregated to help business leaders drive better business decisions.
Ultimately, better text parsing within your BI platform leads to faster analysis and automation by utilizing cleaner data sets. Using these cleaned or structured data sets versus the raw data eliminates the requirement to manually clean the data, which is a tedious process that is both error-prone and time-consuming for your team. These team members gain access to data sets that accelerate the turnaround time for reporting and dashboard creation, empowering your organization to react with real-time insights that provide agility and precision in decision-making.
Choosing the right technique for your text data problem
Successfully using text extraction techniques requires your team to know both when to deploy these techniques and choose the right one for the job. For straightforward situations that involve rule-based searches, such as finding exact words or phrases, pattern matching is your go-to. This approach is efficient for clearly defined extractions, ensuring you capture precisely what you're looking for without overcomplicating the process.
When basic restructuring or cleanup is needed, string functions are the route to go. String functions are commonly used to remove leading or trailing spaces, change text cases, or extract a substring of text based on a fixed position. These functions are ideal for preparing your text fields for further analysis or for standardizing data formats.
When more advanced or flexible pattern recognition is required for extracting text data, regular expressions (Regex) are the preferred tool. Regex enables you to define complex patterns that are used to extract specific information or details from data that varies in formatting. A few examples of information commonly extracted using Regex include email addresses, phone numbers, and dynamic product codes. A major drawback of using Regex functions for text extraction is their tendency to become complex. To avoid unintended matches or performance bottlenecks, start simple and test changes to your functions thoroughly.
If your team is dealing with fields that are structured but inherently messy, then the text-to-columns feature in most BI platforms can be a lifesaver. This technique excels at breaking down a single text string into multiple distinct columns based on a delimiter such as commas or spaces, even when the number of segments varies for each recorded value. This technique is useful for quickly transforming semi-structured data into a more tabular format for easier analysis.
Often, the most challenging parsing scenarios require a combination of the previous techniques. Imagine you have a messy user activity log from a legacy system, where each entry is a single string in a column. An approach could start with a text-to-columns operation, then apply string functions for data cleanup, and finally use a Regex for precise extraction from the remaining text. In this example, the method outlined would isolate and store important information from the legacy system, including log entry IDs, system timestamps, and actions taken. By combining various text extraction methods, you can transform, clean, and create actionable insights from complex textual data.
Using pattern matching and wildcards to isolate key values
A core foundational topic for text extraction is the use of basic pattern matching for text recognition. Pattern matching refers to the process of identifying specific sequences of characters within a larger body of text. Once text has been identified, it can be used to filter, sort, or extract relevant string data with precision. Pattern matching is perfect for quickly isolating data points that adhere to a predictable format and ensuring you have quality data for more effective analysis.
Consider the practical applications of pattern matching. There will be times when you need to match product IDs that follow a specific alphanumeric structure, filter email addresses belonging to a particular domain, or pinpoint invoice numbers based on a known prefix. These are all perfect scenarios for pattern matching, as they involve looking for consistent, rule-based patterns within your textual data. By leveraging this technique, you can quickly narrow your focus to only the information that truly matters.
In text extraction, wildcards are powerful symbols that act as placeholders for other characters and represent unknown or variable text. Wildcards significantly enhance text extraction, expanding pattern-matching capabilities by allowing platforms to create flexible search criteria. Wildcards are integrated across most major BI platforms and supporting languages, including Microsoft Excel, SQL, and common search queries.
While the exact syntax varies across platforms and tools, wildcards are most commonly included between an asterisk (*), question mark (?), or tilde (~) character to identify a sequence of characters. In SQL-based languages, wildcards are preceded by the LIKE operator, while common search engines typically utilize an asterisk (*) or a percent sign (%) before and after the text search criteria. Using wildcards allows your team to find text search criteria regardless of where that substring is located within a text string.
Wildcards provide your team the opportunity to be flexible when extracting text data for analysis and reporting efforts. However, the specific pattern used by your wildcards must be designed to strike a balance between being overly loose and overly specific. An overly loose pattern might return too many irrelevant results and bury your valuable insights in noise. Conversely, an overly specific pattern could cause you to miss important data points that deviate slightly from your strict criteria. The key is to iteratively refine your patterns by testing them against your data to ensure they are both comprehensive and precise simultaneously.
String concatenation and manipulation methods
Let's now explore how combining and splitting strings can unlock new, usable fields from your raw text data. Most BI platforms provide the standard text functions below for reshaping textual information:
- Functions for extracting portions of text:
- Functions for determining the length of characters in a text string:
- Functions for removing extra spaces:
- Functions to concatenate or join text strings:
These tools are fundamental for reshaping textual information into a more analytical format.
You'll frequently find yourself building derived fields to enhance your datasets. For instance, you might combine separate "First Name" and "Last Name" fields into a single "Full Name" field for display or search purposes. Similarly, cleaning up inconsistent delimiters like slashes or hyphens in date or code fields can standardize your data, making it easier to analyze and report on.
For more complex transformations, don't shy away from using nested functions. Nesting functions refers to a function created by embedding one function within another, allowing you to perform multiple operations in a single formula. For example, you could use the TRIM function on a string of text before using the LEFT function to extract a portion of the original text and ensure that no leading spaces interfere with your result. This powerful technique enables sophisticated data cleaning and restructuring.
When constructing nested formulas, prioritize maintainability and readability. Break down complex logic into smaller steps to make the logic more manageable, and use comments or clear naming conventions for your derived fields. This thoughtful approach will not only help you troubleshoot more easily but also ensure that other users can understand and leverage your work effectively in the future.
Mastering regular expressions for flexible, precise extraction
As mentioned earlier in this blog, when your textual analysis requires a more advanced or flexible pattern recognition for extracting data, you should consider regular expressions (Regex).
Regex is a specialized sequence of characters used to define a search pattern. These search patterns are used to match, locate, and manipulate text based on highly complex criteria. The power behind this text extraction technique lies in its ability to go beyond simple string matching and identify patterns that may vary, making it invaluable for messy, real-world data.
This ability to create flexible text extraction functions is evident in the abundance of use cases in business analysis. Imagine needing to pull out all valid US zip codes from a text field, regardless of whether they're 5-digit or 9-digit with a hyphen.
Using Regex, you can create a function that delivers the precision needed to extract these diverse data points. Additionally, Regex functions can be used to easily extract phone numbers from free-form text, isolate specific tags from a string of keywords, or standardize various date formats into a consistent structure.
Let's look at some basic Regex programming syntax.
- \d : used to extract any substring characters that match any digit (0-9)
- \w+ : matches any "word" character (letters, numbers, and underscore)
- . : matches any character in a substring
- * : repeats the preceding character in a pattern string zero (0) or more times
- + : repeats the preceding character one (1) or more times
- The caret (^) acts as an anchor and signifies the start of a pattern string
- The dollar sign ($) denotes the end of a pattern string
- Parentheses () are used to capture groups, allowing you to extract specific parts of a matched pattern as separate data elements.
- .* is a powerful combination, matching any character “.” zero or more times “*”, useful for grabbing everything between two known patterns.
The good news is that Regex isn't confined to programming languages and is integrated into many tools you already use. In Google Sheets, functions like REGEXMATCH, REGEXEXTRACT, and REGEXREPLACE bring Regex power directly to your spreadsheets. Similarly, many BI tools like Sigma offer built-in Regex capabilities for advanced text transformations. SQL databases like Snowflake and the re programming module in Python also support Regex functions, enabling powerful pattern matching directly within your queries for complex text processing.
Advanced text-to-column techniques for structured parsing
When your team is faced with parsing structured fields of text data, the text-to-columns feature or its equivalents are best suited for text extraction. This technique is helpful when your team is dealing with data that resides in a single column containing distinct pieces of information separated by a consistent character. Common examples of these types of data sets include CSV (Comma Separated Values) files, web server logs where fields are delimited by spaces, and any data table containing text strings where data elements are consistently separated.
Parsing with text-to-columns is usually a straightforward process, but it can extend beyond simple single-character delimiters. Your team might encounter multi-character delimiters or even inconsistent delimiters that require a more advanced approach. Most BI platforms offer analytics teams the flexibility to handle these scenarios by requiring a preliminary step to standardize the delimiter before splitting.
A common challenge involves splitting nested fields, where multiple pieces of information are combined within a single delimited segment. For example, if a field contains "John Doe / john.doe@example.com / Analyst", you might first split the text into separate columns using the " / " delimiter. A logical next step would be using helper columns, other string functions, or even Regex on the resulting individual columns to extract additional details. In this example, this would allow the analytics team to extract data for additional fields, including the name, email, and role. Using these techniques to extract granular data from text allows your team to perform analysis that would not be possible otherwise.
Deciding when to use text-to-columns, Regex, or formula-based text extraction boils down to the structure of your raw data. Text-to-columns is ideal when your data has a consistent separator that defines distinct fields, even if those fields themselves are messy. Regex or other formula-based string functions are best reserved for pattern identification when the data within a single field is both unstructured and highly variable. In these circumstances, pattern identification occurs within the field and requires a nuanced extraction of specific patterns.
Making text extraction scalable and collaborative
Now that we've explored various text extraction techniques, let's discuss how to systematize and document your parsing logic for clarity and long-term utility. The goal is to move beyond ad-hoc formulas and transform your text extraction methods into repeatable templates or reusable components. This ensures consistency, saves time, and reduces errors across your analytical projects.
Effective documentation is crucial for any complex text parsing. When crafting Regex patterns or intricate formula logic, always include comments that explain the purpose of each part and any assumptions made. This simple practice makes your work understandable to others, helps your future self when revisiting the logic, and significantly reduces the "bus factor" for your analytical processes.
A significant advantage of modern BI tools like Sigma is their ability to apply text extraction directly on live warehouse data. This means you avoid duplicating logic across different reports or analyses since the transformations occur within the data source itself. This centralized approach ensures that any improvements or changes to your text parsing logic are immediately reflected everywhere the data is used.
Finally, to avoid brittle solutions, make a habit of regularly validating your text extraction outputs. Data sources can change, your assumptions become outdated, and business needs change. Implementing periodic checks and setting up alerts for unexpected data formats will help you proactively identify and fix issues, ensuring your insights remain accurate and reliable over time.
Clean text, clear insights
The verdict is clear: mastering text extraction techniques is not just a valuable skill but a crucial one. Analysts who can confidently parse messy, semi-structured, and unstructured data gain a significant edge. These analysts can transform what was once a data roadblock into a rich source of actionable insights. This capability empowers you and your team to tackle a broader spectrum of business questions and unlock hidden value.
Additionally, text extraction is a core skill for anyone aiming to transform raw and unwieldy data into clean, structured inputs for business intelligence. It bridges the gap between chaotic text fields and the clear, tabular data that BI tools thrive on. This enables organizations to create more accurate dashboards, compile better reports, and make smarter business decisions. The effort invested in learning these techniques pays dividends in efficiency and analytical depth.
We've covered a range of powerful tools, including basic pattern matching, string functions, Regex, and text-to-columns. The true artistry, however, lies in your ability to experiment with and combine these techniques strategically to meet the unique demands of your business. Don't be afraid to try different approaches and iterate until you achieve insightful results.