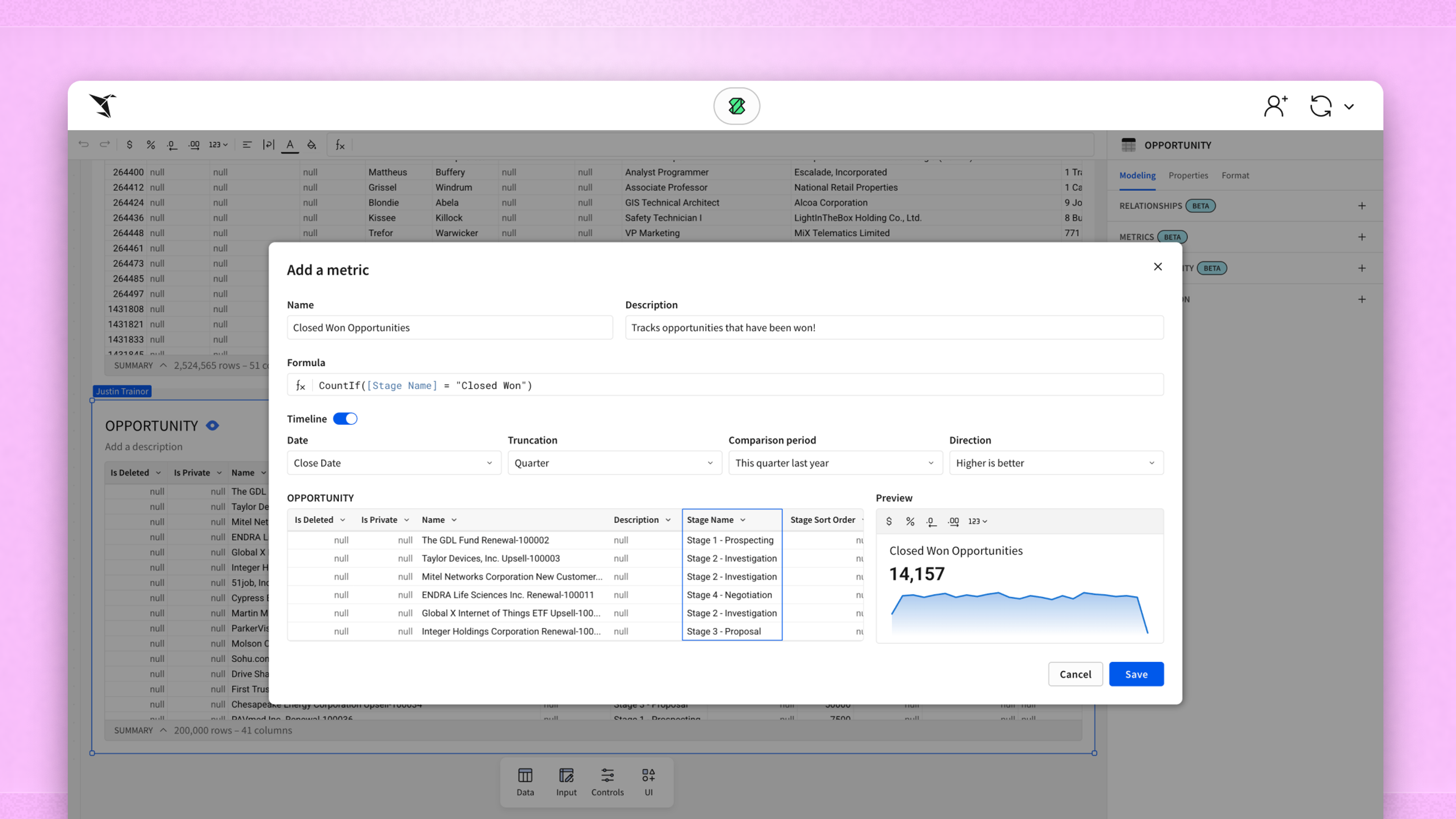
What Is The Difference Between Rows And Columns?

At a glance, rows and columns feel simple: horizontal and vertical. One holds data; the other names it. But there is more to rows and columns than their place in a spreadsheet. The values they hold are the backbone of the very structure of the spreadsheet and the value it holds.
This post discusses more about rows and columns and when they are at their most valuable, as well as what to do when things go wrong or data gets misplaced.
What rows and columns represent
The most basic structures often carry the most weight. Rows and columns may look like a grid of cells, but they carry the logic of the dataset. Every table is built on this foundation. Each row is a single entry: a record of a transaction, an employee, a product, a moment in time. If your dataset is a table of customer orders, each row holds everything about a single order: who placed it, when it was placed, and how much it cost. The row is the unit of observation you're keeping track of.
Columns, in contrast, define the shape of that observation. They describe the attributes like customer name, order ID, date, revenue, etc. If rows are the stories, columns are the questions being asked: Who? What? When? How much?
This structure is deliberate, and tools like Excel and Google Sheets default to this model because it's the easiest way for humans to scan and interpret. SQL databases use similar logic, though they label things differently. Instead of rows and columns, you might hear "records" and "fields." In statistical tools like R or Python’s pandas library, the terms shift to "observations" for rows and "variables" for columns. Despite the change in terminology, the concept holds steady. Data has a shape that determines how easy or difficult it is to clean, join, analyze, or visualize.
Here’s a trick if you’ve ever hesitated over what’s what: columns are usually typed and labeled like numeric, string, date, and rows typically have an index or identifier, either automatically generated or assigned. Columns are the what; rows are the who or when.
Spreadsheets vs. databases: Same structure, different logic
At first glance, a spreadsheet and a database seem interchangeable. Both store data in a tabular format, use rows and columns, and can, technically, be used to answer the same question: “What’s in this data?” That flexibility of merging cells, changing formats on the fly, and editing without warning makes spreadsheets intuitive but also risky. One small change can quietly alter how the data is interpreted, especially once it leaves the spreadsheet. Suddenly, the differences between spreadsheets and databases become much harder to ignore.
Spreadsheets were designed for individual work. They're flexible, visual, and forgiving. You can drop in a note, highlight a cell, merge a header row, or manually fix an error without breaking anything obvious. The structure exists, but it’s fluid, and that freedom can be helpful when you're exploring or calculating, but it also introduces risk. One formatting decision can quietly break downstream logic.
Databases, by contrast, enforce structure through rules. In a SQL table, every column has a defined data type, and every row is expected to follow that format. There's less room for improvisation, but that consistency is exactly what makes reliable analysis possible. You can't decide to add a comment inside a numeric field or sneak a date into a category label. That rigidity is what makes scale and collaboration possible. When managing millions of rows across multiple tables, being able to rely on structure is foundational.
Even the language reflects this shift in mindset. In a spreadsheet, people often describe data in visual terms: “column B,” “row 7,” “top header.” In a database, it’s all about the schema. A “field” belongs to a “record” within a “table.” Analysts talk about joins, indexes, and normalization. The interface disappears, and the structure becomes more abstract, more declarative.
This matters because many of the frustrations in analytics workflows happen at the edges, where a spreadsheet is used like a database or a flat file gets fed into a relational system. That’s where formatting quirks start to cause real problems. You might not notice until something doesn’t filter correctly, a JOIN fails silently, or someone spends hours debugging a report that just needed a consistent column type. Understanding this distinction is what helps you work smarter and faster. It’s what gives structure meaning.
Flipping the table: Changing structure for better analysis
Data isn’t static. The same table that works for one analysis might feel impossible to use in another. That’s where reshaping comes in; reorganizing how the data is structured without changing the values. One of the most common transformations is turning rows into columns or vice versa. On the surface, this sounds like a formatting choice, but in practice, it’s often the difference between an analysis that works and one that never gets off the ground.
Take a common example: survey data. You export results and see each question as a row, with respondent answers stretched across columns. This might look fine for reading, but if you want to analyze how a single respondent answered multiple questions, that structure fights you. You need each respondent to be a row, not each question.
That means flipping the table and pivoting or transposing the data so the structure fits the task. Spreadsheets let you do this quickly with copy/paste and transpose features. Select your data, use Paste Special, and choose Transpose. It flips the table's orientation, and what was once a column header becomes the start of a new row, and vice versa. That’s fine for minor adjustments or exploratory work.
But reshaping needs to be more deliberate when working at scale or inside a tool built for analysis rather than formatting. Tools like SQL let you pivot (turn rows into grouped columns) or unpivot (do the reverse). You define what becomes a header and what stays as a value. The goal is to reshape with control, not guesswork.
These transformations change how filters behave, aggregations roll up, and charts display relationships. In some cases, reshaping is what allows your logic to work at all, and because structure matters downstream, reshaping early and deliberately means fewer problems later. You spend less time troubleshooting and more time analyzing.
How structure affects analytics workflows
It’s easy to treat structure like a setup task; something you get right at the start and then move on from. But in practice, structure is constantly in motion. As questions shift, so does the shape your data needs to take. Filtering, grouping, and joining depend on rows and columns behaving predictably.
Say you’re building a report to track customer behavior. You want to filter by product category, group by region, and sum total purchases. If each product is spread across separate columns or the region is buried in a merged cell at the top of a sheet, the logic breaks down fast. You work harder to force insights from data, simply because it's in the wrong shape.
Columns carry the attributes you analyze, and when they're formatted consistently, you can sort, group, and summarize without friction. Aggregations make sense, filters behave the way you expect, and charts tell the story instead of distorting it. Rows, on the other hand, create structure through repetition. Each one is a single entry, moment, or action. That consistency makes row-level operations like deduplication, slicing, or indexing possible. If one row includes multiple values separated by commas, it’s a workaround waiting to cause a problem.
These problems compound when you move across tools. A spreadsheet might let you get away with inconsistent formatting; a SQL join won’t. A visualization might render the chart anyway, but someone will notice that the counts are off or that a category went missing. Structure, when it works, is invisible. When it fails, it becomes the problem everyone chases.
Even small things like using the same column name across tables or keeping date formats aligned can save hours later. Structure is a precondition for analysis; it actively shapes the decisions you can make and the confidence you have in them.
What happens when structure fails
You don’t always notice structural issues right away. One of the most common culprits is treating formatting like structure. Merged cells, for instance, might look cleaner in a spreadsheet, but that merged header spanning three columns? It tells you nothing about the actual values beneath it. Worse, it can throw off column detection entirely when exported or loaded into another tool. Then there’s the problem of headers doubling as data. In some reports, what should be values are used as column titles. This might work visually when scanning a table, but everything becomes harder when you try to pivot, filter, or chart that data. You're forced to reshape it before you can even begin analysis.
Inconsistent data types are another subtle breakdown. A single column mixing numeric and text values might not look alarming, but that inconsistency gets in the way when it’s time to run calculations or joins. Sorting fails, aggregations throw errors, and unless you're looking closely, those issues often get blamed on the tool rather than the structure beneath it. Even small things like putting totals in the last row of a table can cause ripple effects. Suddenly, your metrics are inflated, your filters behave unpredictably, and the person reading the report asks uncomfortable questions about accuracy.
These lead to reporting errors, including duplicated counts, missing data, and faulty comparisons that quietly distort your story. They eat up time and happen more often than most teams would like to admit. Recognizing the most common failure points puts you in a better position to prevent them. Structure doesn’t need to be flawless, but it needs to be respected because once trust in the structure erodes, everything built on top of it starts to wobble.
What to expect from your analytics tools
If structure is the foundation of your workflow, your tools should make it easier to keep that foundation intact. At a minimum, your analytics platform should make rows and columns visible, editable, and traceable. You should be able to see when a column’s type shifts from number to text, or when a missing value starts affecting your totals.
More advanced tools will help you work with structure across datasets. That means handling joins cleanly, preserving column types through calculations, and flagging issues when something doesn’t match up. Ideally, the system does enough to catch structural risks early without hiding the logic from you. The best tools help you shape data on your terms, and they stay out of your way when you’re doing the real work.
The invisible structure behind every clean dataset
Most people working with data don’t think about rows and columns once the table looks right. But the difference between “looking right” and “working right” lives in the structure. When structure holds, analysis flows. When it breaks, you feel it when it’s least convenient.
Clean data is about accuracy and reliability. You want to be able to open a file, run a query, or share a dashboard and trust that the logic still holds. That trust starts with something as simple as where the data sits, what each row represents, what each column describes, and if those decisions stay consistent from one step to the next.
Understanding the shape of your data is part of the craft. It’s what separates analysis that scales from one-off fixes that barely hold together. Structure guides how you think, no matter what tool you’re using or the size of the dataset. Thinking with structure lets you ask better questions and get better answers in return. So next time you’re staring at a messy export, a broken join, or a chart that refuses to sort, zoom out. Before diving into formulas or filters, look at the structure. Then everything else has a place to stand.