Sigma’s Innovation: Alpha Query and Partial Evaluation Explained

We have built Alpha Query at Sigma - a query execution engine for the browser.
Introduction to Alpha Query
Alpha Query is a columnar vectorized batch-pipelined Volcano query engine. It is an interpretive engine with its own byte code and virtual machine using WebAssembly to achieve native code execution speeds in the browser.
The most novel idea implemented by Alpha Query is partial query evaluation by query difference, which I will dive into in the rest of this blog.
Understanding partial query evaluation and its importance
Interactive data exploration queries can quite often leverage partial query evaluation based on the results of previously issued queries. This is extremely valuable in big data exploration, where it can be expensive to run every query from scratch. When data is remote, e.g. in a cloud data warehouse, and every query, even inexpensive, incurs a roundtrip, reduced latency improves user experience.
Sigma's approach to partial evaluation
Sigma is a cloud analytics platform that uses an intuitive interface based on familiar spreadsheet features to give business users instant access to explore and gain insights from their data warehouse. The ad-hoc reactive nature of Sigma makes it amenable to partial evaluation.
The general problem of partial evaluation is to find a way to compute the next query from a set of query results. Data warehouses can also maintain a set of prior results and tackle this problem, however, none of the data warehouses that Sigma is interested in seem to do it. It's more challenging for general SQL than it is for queries represented in the Sigma query language.
Understanding Sigma queries
A Sigma query defines group-by-dimensions and sub-dimensions called levels. It's possible to define columnar expressions and level operations, such as sorting or filtering, that cross-level boundaries both ways without causing cycles in the data dependency graph. Evaluation of common sub-graphs can be skipped and the results carried over. If the graph difference, between old and new, can be computed over results of common sub-graphs then partial evaluation produces the desired result.
The accidental query result cache contents can be augmented by prefetching queries that are likely to be useful for further query evaluation based on heuristics. The rule of thumb is to prefetch data that the user did not request in order to maximize the odds of successful partial evaluation in the future.
Sigma workbooks and hierarchical organization
Sigma queries are embedded in user-created documents known as workbooks. Sigma workbooks organize visual elements hierarchically so child elements evaluate over one or more parent elements similar to SQL views. The most common heuristic is to prefetch parent elements based on the history of workbook usage, where one or more child elements can compute from that result without making a data warehouse request.
Query graphs and their structure
A Sigma table contains one or more hierarchical group levels where each next level sub-groups the upper level.
Query difference is computed from query graphs. A query graph node represents one of the following operations:
- Scalar column formula
- Aggregate column formula
- Window column formula
- Level group-by
- Level sort
- Filter
- Join
If the graph has an edge connecting node A to node B then A must be evaluated before B, we say that B depends on A. The rules for drawing graph edges are as follows:
- A column node depends on all column nodes referenced by its formula
- A sub-group level node depends on the higher group level node
- A sort node depends on the group-by node at the same level
- A window column node depends on the sort node at the level where the column is computed
- An aggregate node depends on the group-by node at the same level
- An aggregate node depends on filter nodes on columns of lower levels
Computing query difference
We can only compute the new query result based on the query difference if query graphs are acyclic. This rule is stricter than the Sigma SQL generator restrictions, which can sometimes generate and run the query even if the query difference rules one or both graphs cyclic. This is rare.
The new graph is evaluated bottom-up. If a node and its graph sub-tree is unchanged from the old graph and its value exists in the old result, the value of the node is carried over to the new result. If a node depends only on the nodes we have already carried over or computed, it can be computed. This process continues until all nodes in the new query graph are either carried over or computed (technically the process is split into building an execution schedule and running it, to avoid unnecessary computation and memory waste if in the end, we have to bail for some reason).
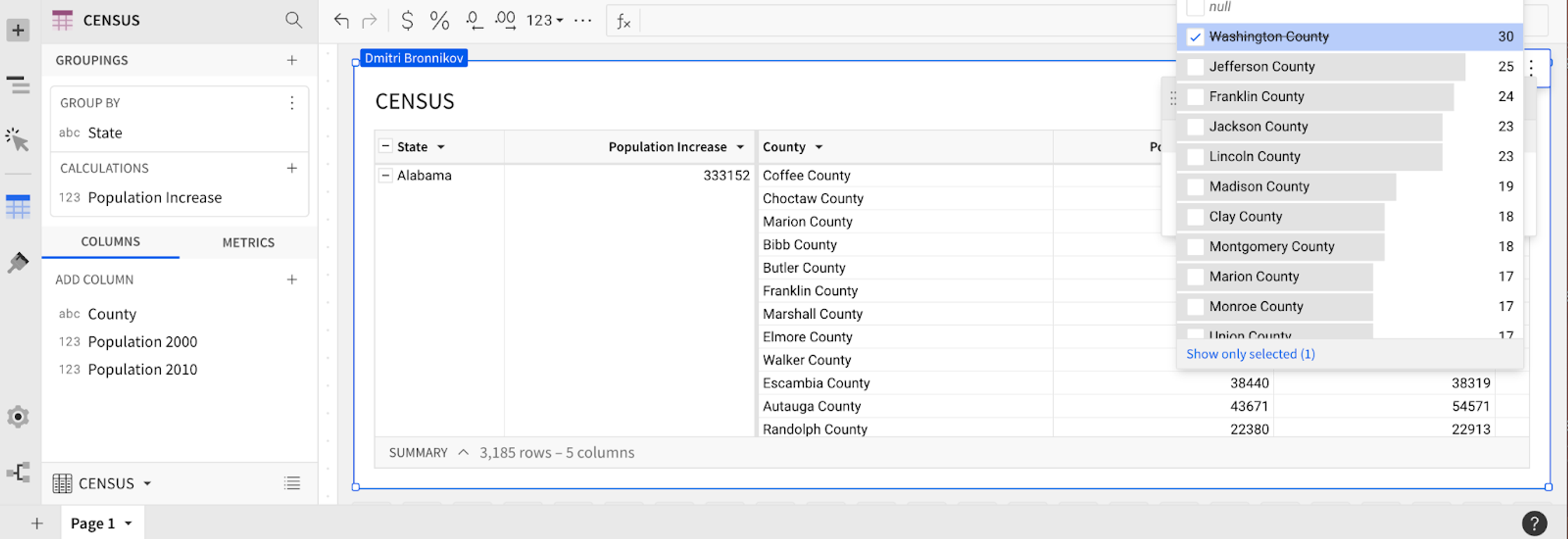
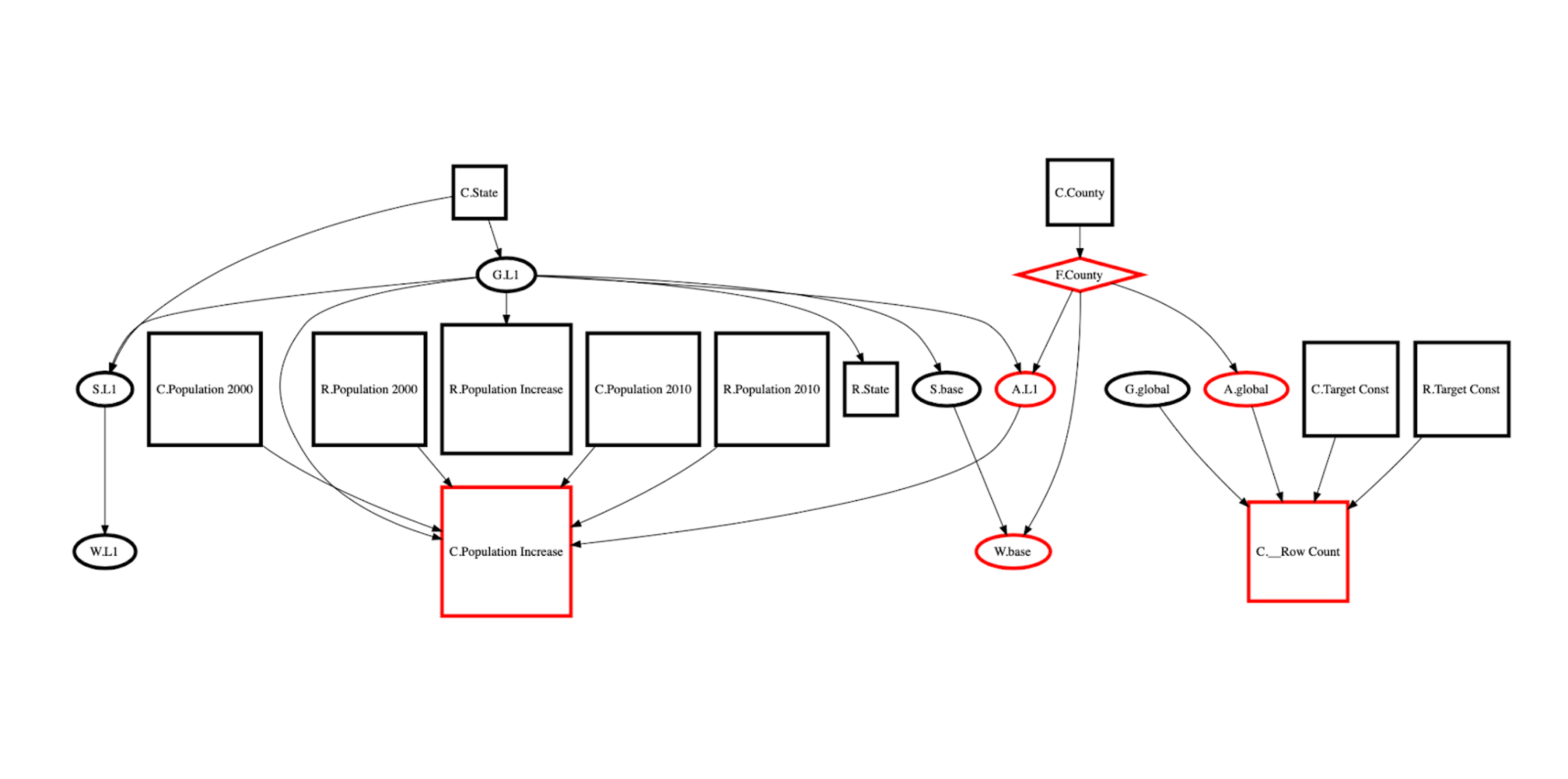
Example: Applying a Filter
In the example below, the user adds a filter (exclude Washington County) to the Census table grouped by State with an aggregate column that aggregates population increase per state. The filter is applied at the base level and invalidates the State level aggregates. Black nodes are carried over, red nodes are recomputed (if they existed in the old query graph) or computed (nodes that are added to the new query graph). The node type is denoted by the first letter of the node name, e.g. C.State is the State column, S.L1 is the sort node at level L1, A.L1 is the aggregate sentinel that precedes all aggregate column nodes at level L1. There are other special sentinel nodes introduced to reduce the number of nodes in the graph, e.g. all nodes that must be computed before level L1 aggregates are connected to A.L1 instead of connecting every such node to every aggregate column at level L1.
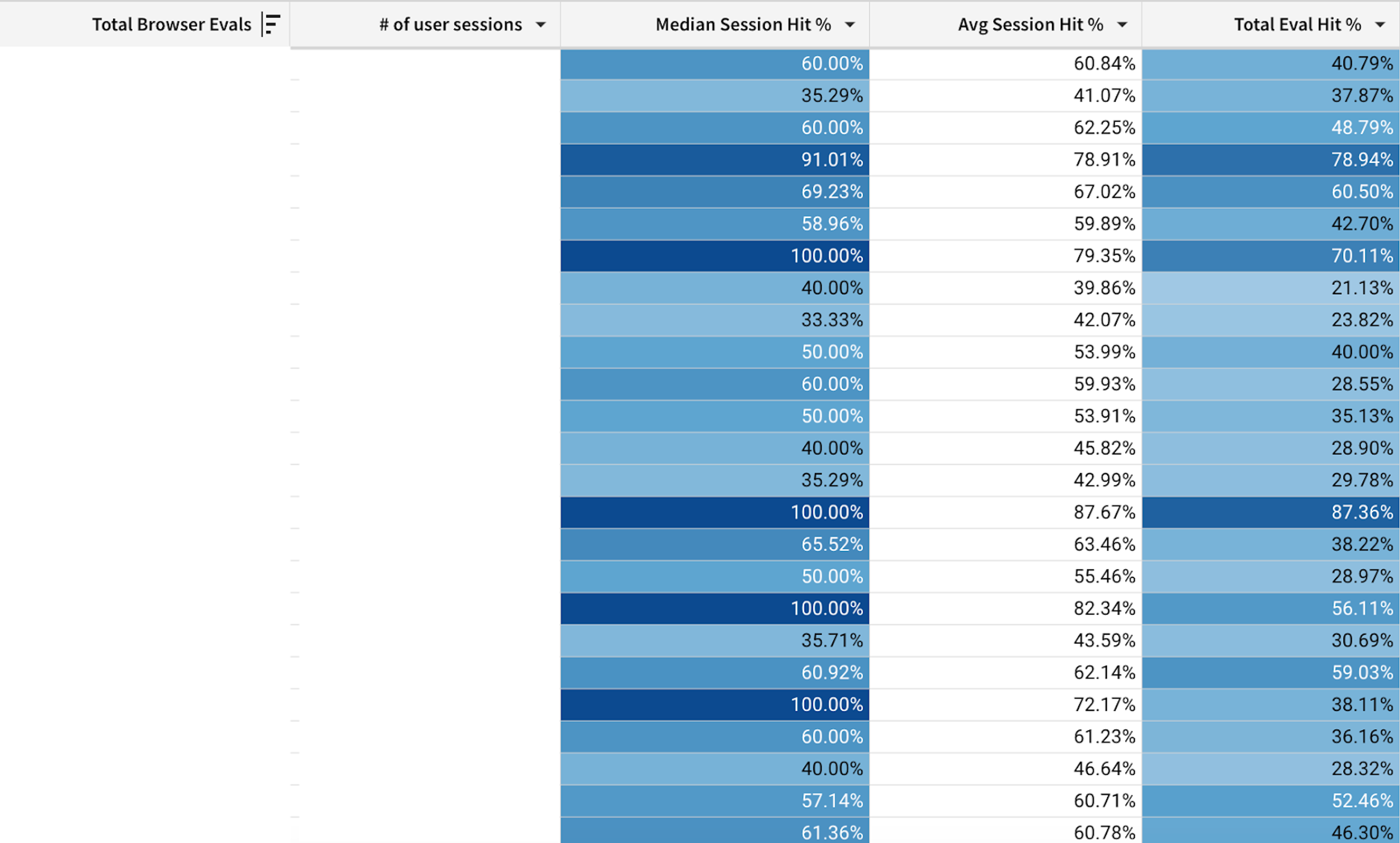
How well does it work for the user? Our observation is that it depends on the usage pattern. The table below shows the percentage of Sigma queries evaluated locally without reaching out to the data warehouse. Every row reports one customer organization. The table is ordered by the number of local query evaluations (hidden), not any of the percentages. The screenshot captures the top of the table, the whole table is about one thousand rows long.
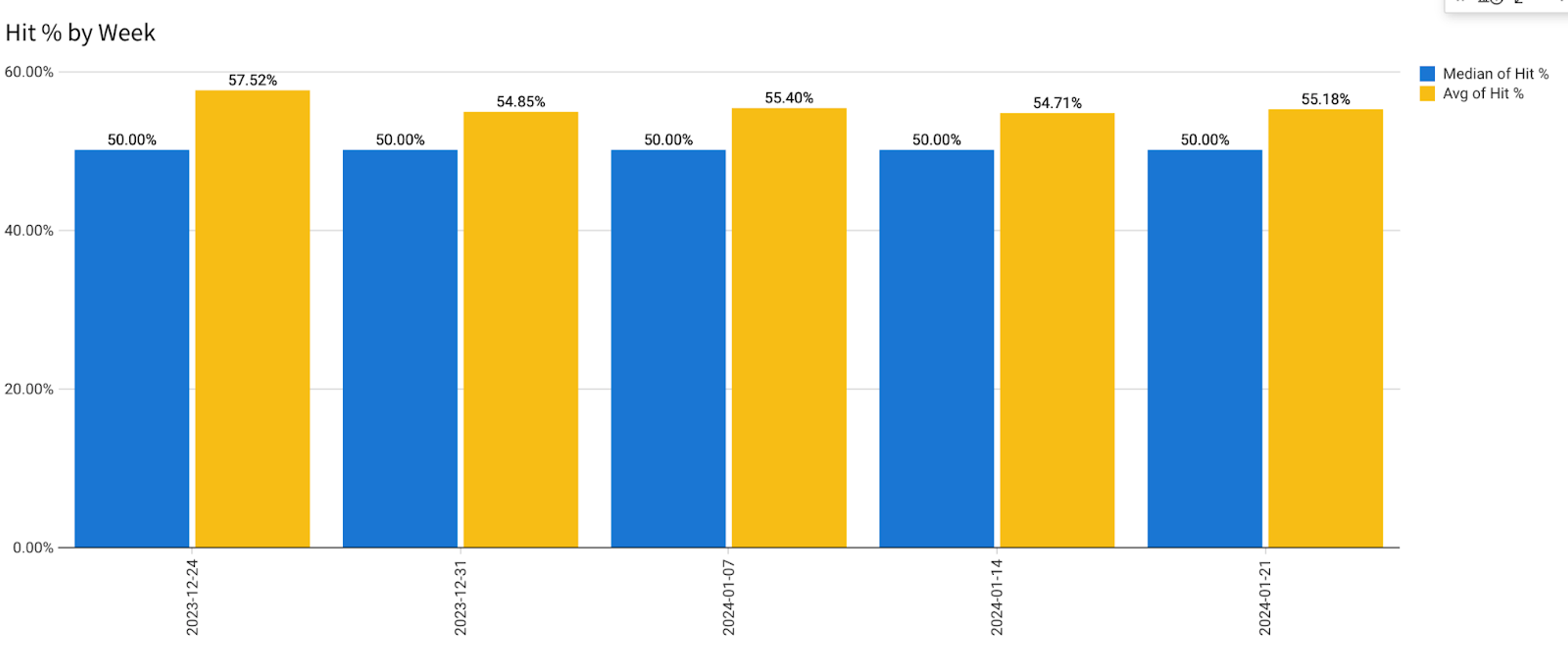
The next picture shows weekly dynamics across all users.
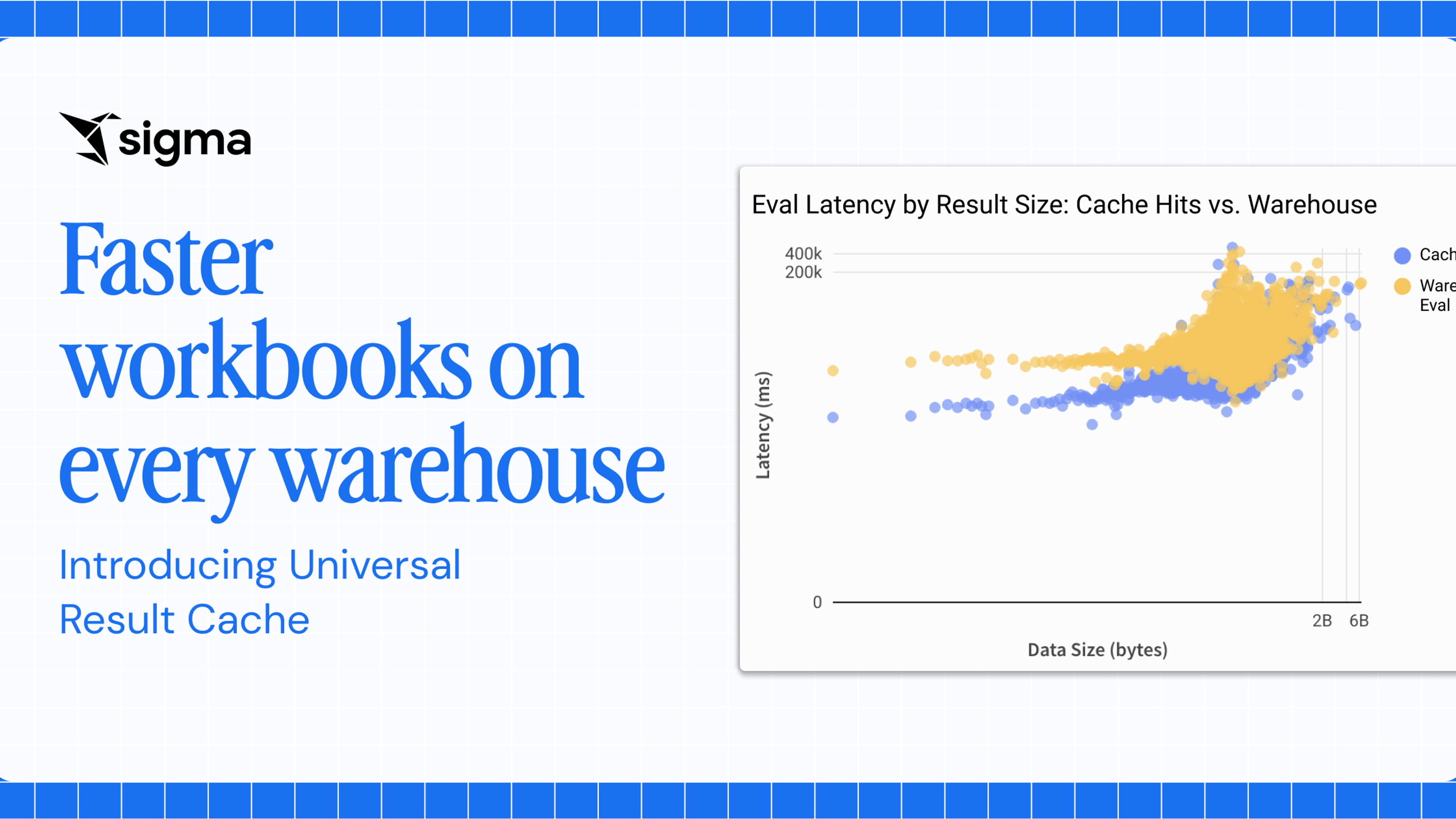
Alpha Query represents a significant technological advancement that optimizes how Sigma processes data queries. Traditional methods of sending queries to cloud data warehouses can be slow and expensive. With Alpha Query, we harness the power of the user’s existing hardware by executing queries directly in the browser on the user's laptop, provided sufficient data is already available locally.
By employing techniques such as partial query evaluation, we can compute new results from existing data in the browser, minimizing the need for cloud queries. This approach not only accelerates data processing but also significantly reduces cloud costs.
The technology behind Alpha Query is technically fascinating, demonstrating our investment in pushing the boundaries of browser-based analytics. With these innovations, Sigma continues to enhance the user experience, making data querying more seamless and efficient.
Join us at Sigma Computing
At Sigma, we are dedicated to pushing the boundaries of what’s possible in data analytics and invite passionate engineers to join our team. If you want to work on cutting-edge projects and shape the future of data exploration, apply now to one of our open roles.