A Practical Guide to Using Sigma with Databricks

The purpose of this article is to highlight three significant considerations when architecting Databricks for use with an Analytics platform such as Sigma. The three areas we will cover are:
- The type of Databricks SQL warehouse that should be used.
- The type of tables that should be created in Databricks.
- Considerations when partitioning Databricks tables.
Classic vs. Serverless SQL Warehouse
Connecting Sigma to Databricks requires a Databricks SQL warehouse. When creating a Databricks SQL warehouse, customers can decide to use a Classic or a Serverless SQL warehouse as the compute resource for running SQL queries.
Databricks architecture consists of a control plane and a data plane. The control plane includes the backend services that are always managed by Databricks in its own cloud account. The data plane is where data is processed by clusters of compute resources. One of the most important differences between the Classic data plane and Serverless data plane is where the compute resources run. In the Classic data plane, Classic SQL warehouses exist in the customer’s cloud account whereas, in the Serverless data plane, Serverless SQL warehouses exist in Databricks’ cloud account.
We would like to investigate which type of warehouse is a better choice depending on the type of analytics workload. We will look at two types of analytics workloads:
- A workload where users are constantly using Sigma, and therefore, queries are expected to execute against the warehouse every 5 minutes during business hours. An example of such a workload would be a large number of users in an organization using Sigma for operational analytics.
A Classic warehouse can take several minutes to start. During startup, queries have a high chance of timing out. To avoid a degraded user experience, a classic warehouse for this scenario can be set with an auto-stop value of 10 minutes to avoid shutting the warehouse down during business hours. Assuming 8 business hours in a day, the warehouse will stay up for 8 hours and 10 minutes/day.
Serverless compute, on the other hand, brings a truly elastic, always-on environment that’s instantly available. Auto-stop for a Serverless warehouse for this scenario will also be set to 10 minutes. The warehouse will again stay up for 8 hrs and 10 minutes/day.
- A workload where usage is infrequent. Let’s assume once every hour during business hours. An example of such a workload would be periodic reporting or a small set of users in a small organization.
For this scenario, auto-stop for a Classic warehouse will be set to 1.5 hours to avoid queries from timing out during business hours. The warehouse will stay up for 9.5 hours/day.
Auto-stop for a Serverless warehouse for this scenario can be set to 10 minutes, due to the always-on nature of the compute environment. Assuming queries take 2 mins to run, the warehouse will stay up for 96 mins/day.
![Sigma on Databricks][HREF: /resources/ebook/unlock-data-democratization-with-sigma-on-databricks](https://cdn.sanity.io/images/9i48iita/production/6adad6e36151dda23e22d2bbb59955a05ef53ff4-2400x601.png?w=3840&q=75&auto=format)
Enterprise Edition
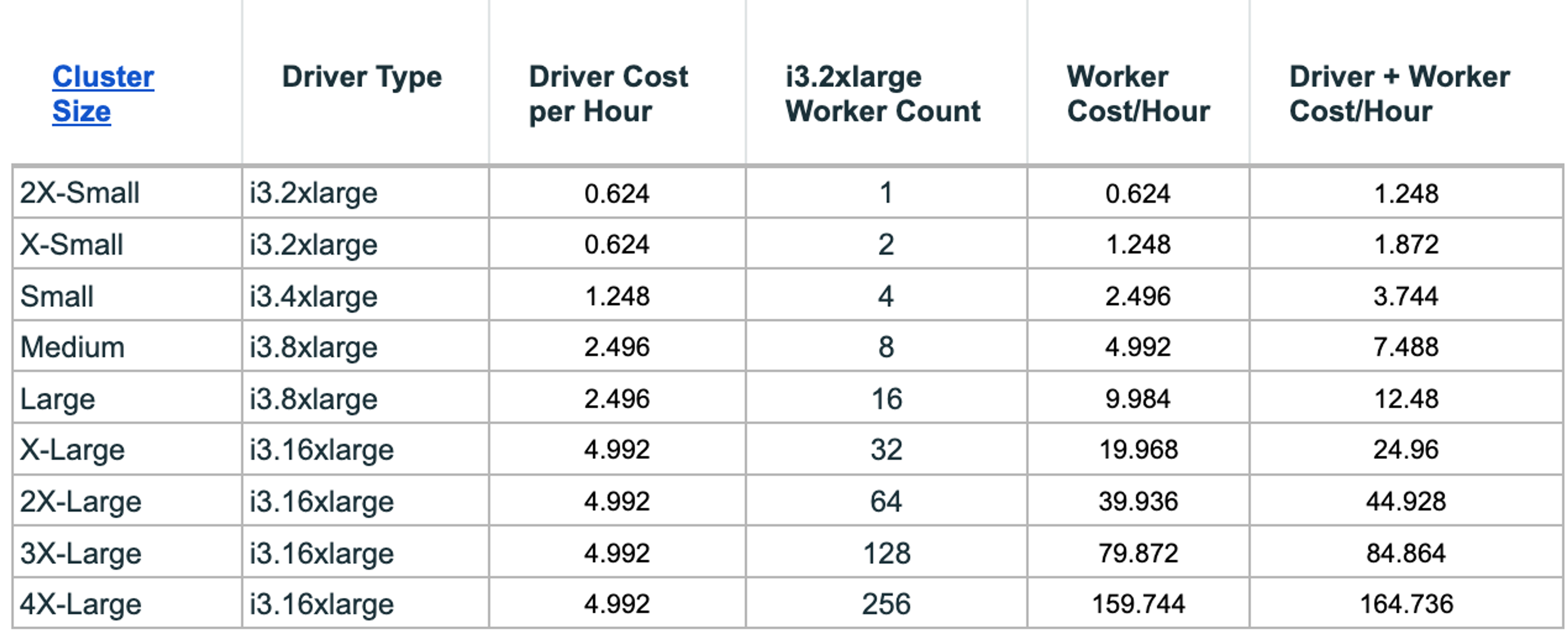
Classic SQL Compute at $0.22/DBU/hour
Serverless SQL Compute at $0.70/DBU/hour
On-Demand hourly rate for an AWS i3.2xlarge EC2 instance of $0.624
The following table lists the AWS costs incurred for each Classic cluster size. Note that these costs do not apply for a Serverless warehouse.
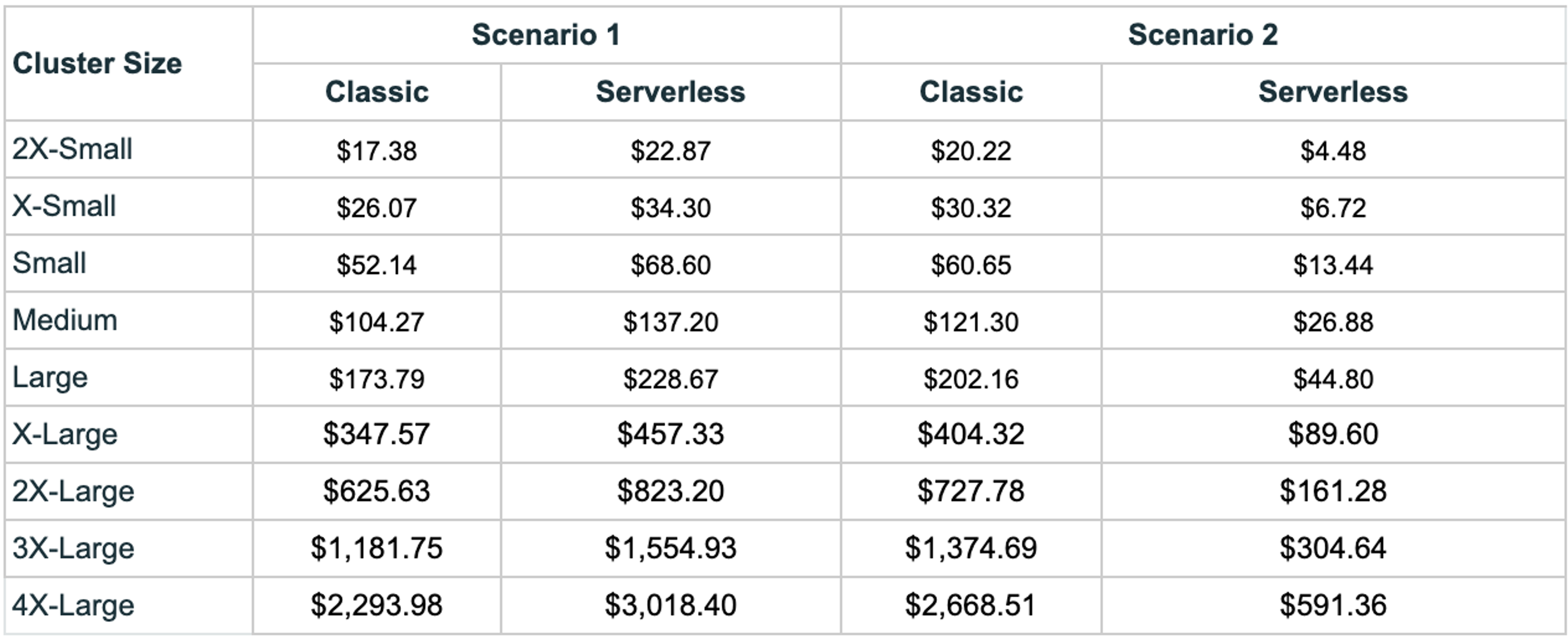
Even though Classic is slightly less expensive for scenario 1, consider the following:
- the additional benefits of using a Serverless SQL warehouse as summarized in this Databrick blog
- the continued investment being made in Serverless data plane by Databricks, and
- the fact that personnel cost associated with maintaining cloud infrastructure for the classic data plane is not included in this cost analysis
Therefore, it is our conclusion that using Serverless SQL warehouses, even in Scenario 1, is advisable due to the overall benefits it provides despite the slightly higher cost.
![Sigma on Databricks][HREF: /resources/ebook/unlock-data-democratization-with-sigma-on-databricks](https://cdn.sanity.io/images/9i48iita/production/f2d7f054c1195f7b06f92d56c975ac1dd819f3c6-2400x600.png?w=3840&q=75&auto=format)
Correctly architecting data for downstream consumption within Databricks is critical to Sigma’s performance. For that reason, Sigma recommends following the data design pattern of Medallion Architecture.
This architecture builds data-quality levels based on how data flows through the platform. Also referred to as Multi-Hop architecture, this medallion architecture classifies:
- Raw or newly ingested data as Bronze
- Transformed, cleaned and normalized data as Silver
- Curated business-level data as Gold.
Following this architecture simplifies the data model and creates an easy-to-follow pattern for all your data sources before analyzing and visualizing using Sigma.
Within this architecture, there are multiple types of acceptable data formats. These formats can be categorized as either Delta or Non-Delta.
A Delta table uses the Delta Lake open-source protocol. This protocol brings reliability to tables within Databricks via ACID transactions, scalable metadata handling, and unified processing of streaming and batch data.
You can also store non-Delta tables and objects within Databricks.
- Supported file formats include TEXT, AVRO, CSV, JSON, JDBC, PARQUET, ORC, LIBSVM, and a fully-qualified class name of a custom implementation of org.apache.spark.sql.sources.DataSourceRegister.
- Data sources include external systems such as Amazon Redshift, Azure Cosmos DB, Azure Synapse Analytics, Cassandra, Couchbase, ElasticSearch, Google BigQuery, MongoDB, Neo4j, Redis, Snowflake, and SQL databases using JDBC.
Non-delta tables are not backed by Delta Lake and do not provide the benefits that delta tables do. These are often your raw sources of data and should not be directly queried by Sigma.
For example, retrieving a count of all rows from a non-Delta CSV table with approximately 2-3 million records takes 2-3 minutes. A query to calculate a measure grouped by one column takes even longer.
For the same table created as a Delta table, a count of records takes less than a second, and a query to calculate a measure grouped by one column takes ~2 seconds with a small SQL warehouse.
This image shows how medallion architecture works with Sigma:
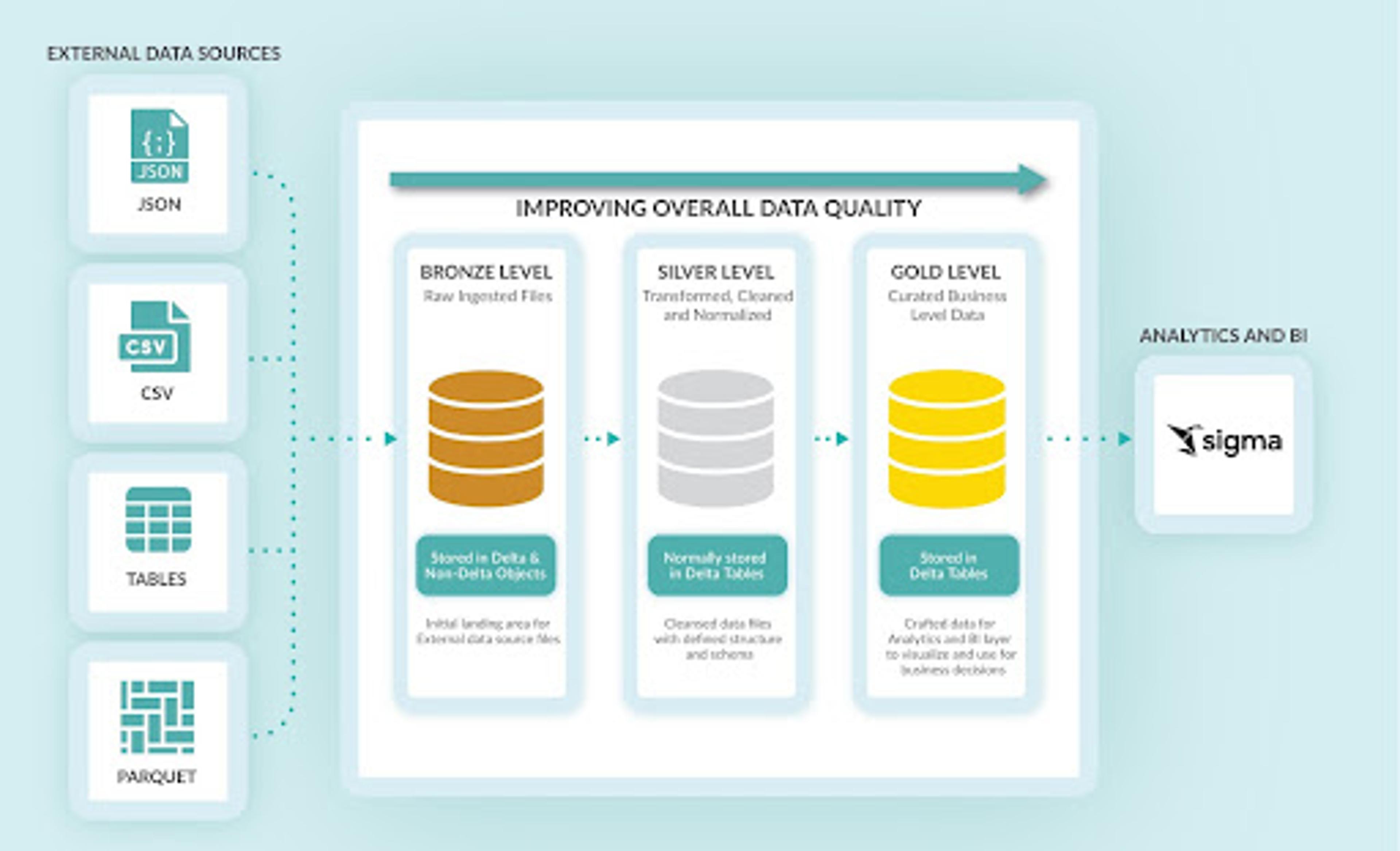
- Bronze-level (raw ingestion) data can be stored in both Non-Delta and Delta tables and objects. Non-Delta objects allow file format flexibility without requiring a defined schema. Delta protocol now supports schema evolution making it possible to store structured, semi-structured and unstructured data in Delta tables.
- Silver-level (transformed, cleaned, and/or normalized) data is normally stored in delta tables. Delta tables help protect the data at this step in the process due to ACID transaction guarantees.
- Gold-level (curated business) data should always be stored in Delta tables. As stated above, this will ensure that data has all the added benefits from the Delta Lake protocol, including the previously mentioned ACID transactions and improved processing.
Following this recommended paradigm within Databricks, allows the data to be properly ingested, cleaned and prepared for Sigma. Sigma’s connector to Databricks was built specifically with the Delta protocol in mind. All data analyzed within Sigma should be stored in Delta tables for optimal performance.
This is arguably the simplest of the three items discussed in this whitepaper. Similar to other warehouses, Databricks allows a table to be partitioned using a set of columns. To use partitions, a set of partitioning columns are defined when creating a table by including the PARTITIONED BY clause. When inserting or manipulating rows in a table Databricks SQL automatically dispatches rows into the appropriate partitions.
Using partitions can speed up queries against the table as well as data manipulation. However, partitioning columns need to be selected carefully. For example, assume a sales order table has a date column which stores the order date. If the order date column is used for partitioning, but analytics workloads use quarter or year as filters, partitioning can in fact slow queries down as multiple partitions will need to be scanned to aggregate data for the quarter or month. In this example, a partition on the quarter of the order date is prudent. The performance impact can be dramatic depending on the number of rows in each partition, going from many minutes to a few seconds.


