What to Know Before You Implement Embedded Analytics
Most embedded analytics projects fail to scale for reasons that have nothing to do with the implementation itself. Data model design, tenant isolation, performance architecture, and licensing determine whether the build holds up. Get any one of them wrong and the rework is expensive.
Sigma's documentation covers the mechanics of implementation well. This is about those earlier decisions and the judgment calls they require.
How should you design a data model for embedded analytics?
A data model for embedded analytics needs to meet three requirements an internal reporting model usually doesn't:
- It has to make sense to users who didn't build it.
- Transformation has to happen before data reaches the analytics layer.
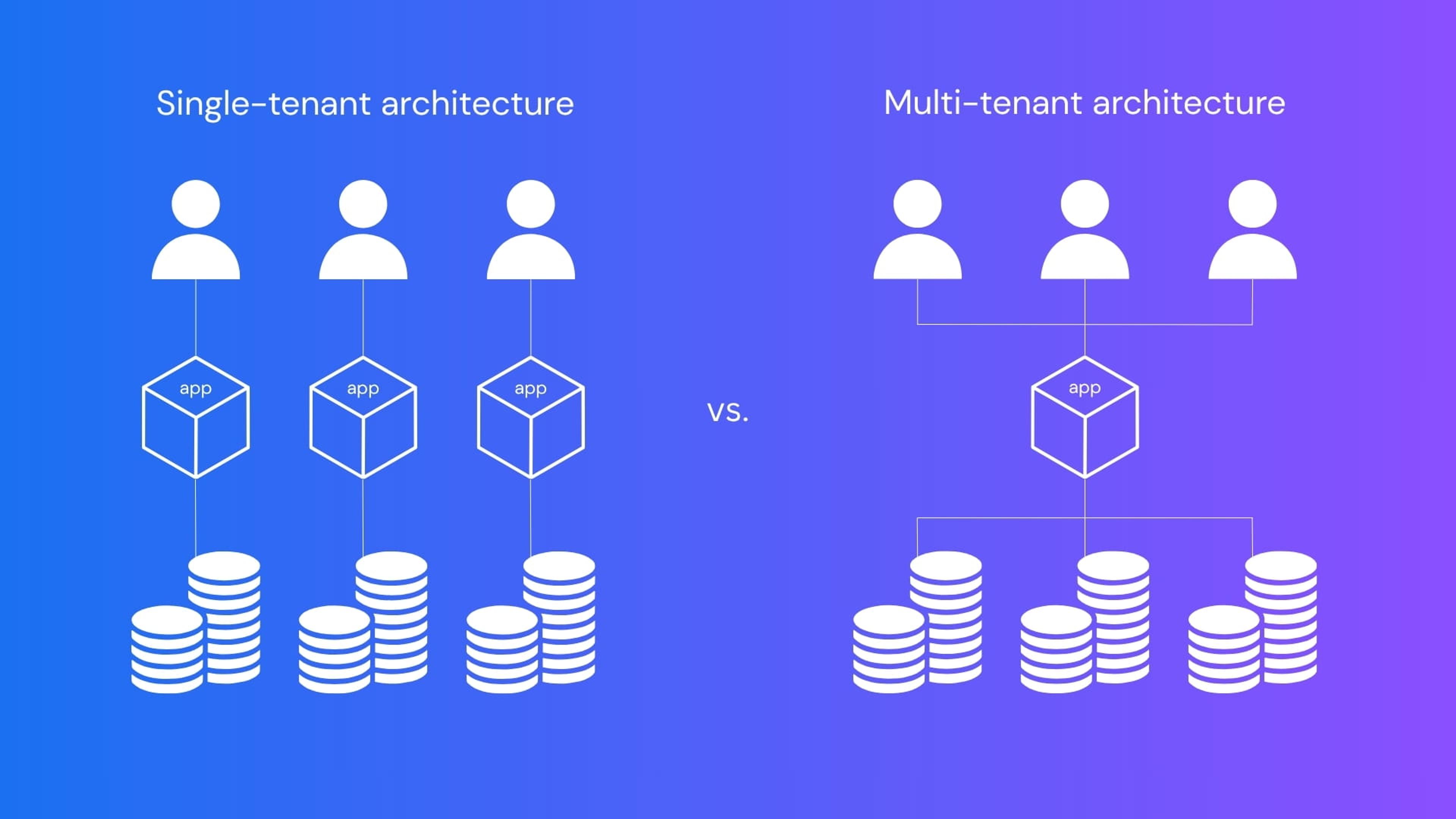
- Tenant isolation has to be built in from the start.
Most teams skip this work because connecting directly to existing data sources feels faster. However, this is only until you need to support multi-tenancy, self-service exploration, or any capability that requires the data to be structured with those use cases in mind. By that point, the analytics layer and the production application are often tightly coupled, and untangling them is more expensive than building the model correctly from the start.
Let’s dig in a little more on the specifics of these three requirements:
- The data model must make sense to end users
If your end users will eventually do self-service exploration, they need to be able to look at a data model and understand how the pieces relate to each other, which dimensions join to which facts, and what each field actually represents. Data that makes perfect sense to the person who wrote the SQL is often opaque to everyone else. That opacity either kills self-service before it starts or creates a support burden you didn't budget for.
- Transformation belongs upstream
Do the transformation work before the data reaches the warehouse, so that your analytics layer can query clean, pre-shaped tables. This keeps costs down and performance predictable—and great performance is one of the key reasons to choose an embedded analytics solution that’s native to the cloud data warehouse.
- Plan for multi-tenancy from the start
If your product will serve multiple customers who should be isolated from each other's data, retrofitting that assumption later is one of the most expensive fixes in embedded analytics. Instead, make sure to plan ahead and build in multi-tenancy needs to the data model from the start.
Tenant isolation is an architecture decision
Tenant isolation tends to get treated as a security checkbox rather than an architecture choice with real operational consequences. Customers should only be able to see their own data. The right approach to achieving that depends on how your data is structured and how many customers you expect to manage.
Row level security
Row-level security applies filters at query time to restrict which rows a given user can access. It is flexible and scales well because the access rules can be powered by user attributes that you assign on demand. The downside is that it requires careful, consistent configuration. A single misconfigured policy can expose data across tenants, and that exposure may not be obvious until someone goes looking for it. Row-level security also requires ongoing governance: who owns the configuration, how it gets tested when the data model changes, and how it gets audited over time are questions worth settling before you commit to this approach.
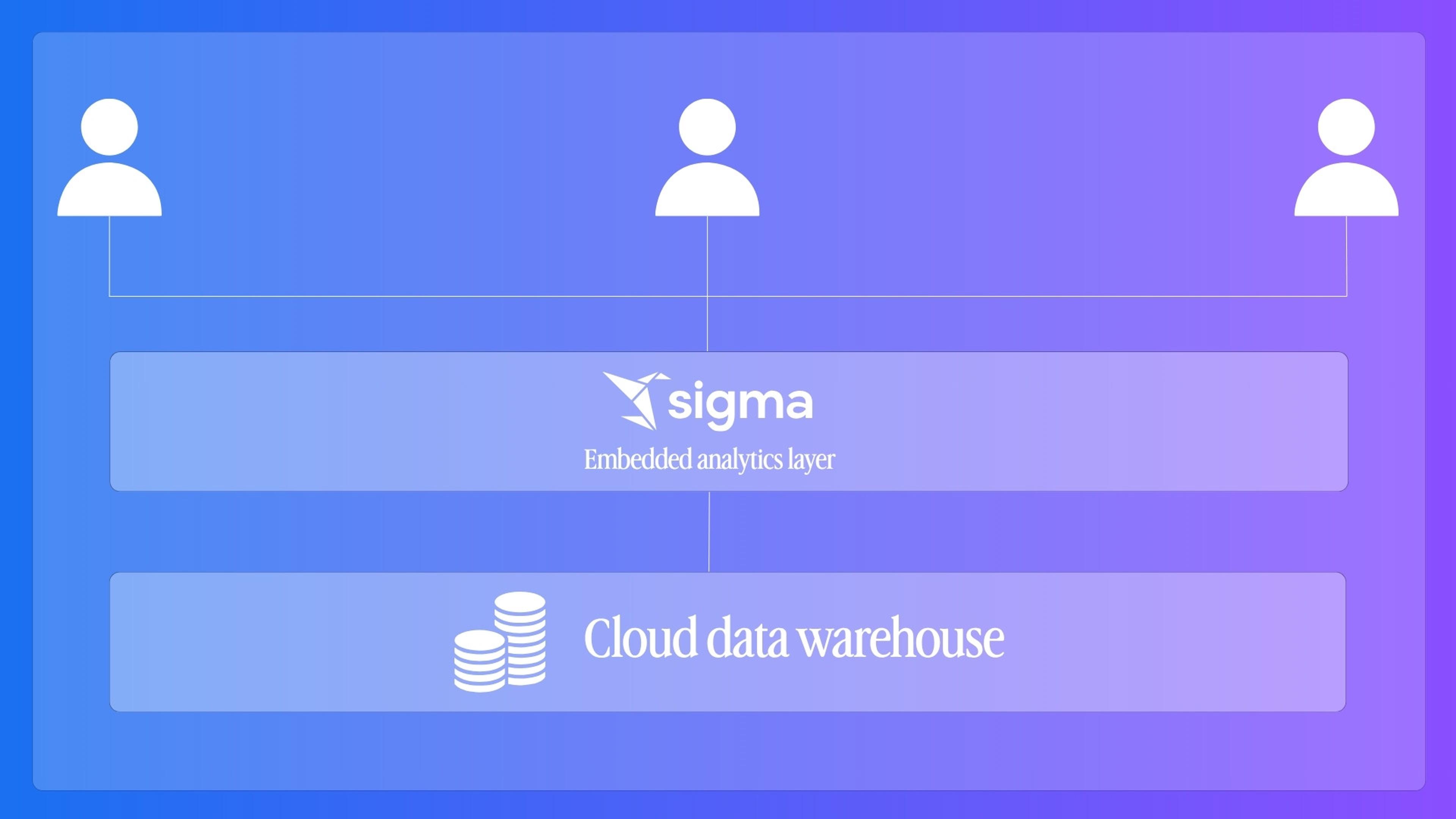
Connection-level isolation
The alternative to row-level security is to isolate at the connection or schema level, where each customer's data lives in its own container, separate from every other customer's. Sigma supports this through connection swapping, where each tenant gets routed to their own data source at runtime. The security boundary is cleaner because you're not filtering within a shared dataset; you're separating at the infrastructure level. The tradeoff is operational overhead: every new customer means a new set of resources to provision and manage. That's manageable at low customer counts and becomes a real cost center at high ones.
Sigma Tenants takes this further, giving each customer their own isolated Sigma organization — worth evaluating if your use case involves strict data sovereignty or you're running a managed service model.
The dimension you choose to isolate on matters as much as the mechanism. Isolating by dev versus prod environment, for example, still leaves all your end customers in the same pool. For most embedded deployments, the right isolation dimension is by end customer, so that each of your customers' users operates in a context scoped to their organization.
What causes performance problems in embedded analytics at high user volume?
Performance problems in embedded analytics almost always trace back to three decisions made before implementation:
- data model shape
- warehouse partition and clustering strategy
- query concurrency configuration.
By the time users run into issues, all three of those decisions are expensive to reverse.
The shape of your data model has an outsized effect on query cost and speed. Cloud data warehouses handle joins well, up to a point. After enough sequential joins against large tables, even tables that look small after initial filtering can become expensive to combine. Teams that perform best at scale have invested in understanding the query patterns their analytics layer will generate and shaped their data accordingly, pre-aggregating where appropriate and limiting the joins that have to happen at query time.
Partition and clustering strategy in the warehouse affects how much data has to be scanned to answer a typical query. If most of your users are asking questions about the last two weeks of data, and your warehouse is not configured to efficiently skip everything outside that window, you are paying to scan data that contributes nothing to the answer.
Query concurrency, meaning the behavior of the system when many users are querying simultaneously, depends partly on how you configure warehouses within your data platform. Most cloud warehouses support the ability to route queries from different user groups to different compute resources, which lets you allocate capacity in proportion to the demand each customer segment generates. Planning for this early means you can size your warehouse configuration against your actual customer tiers. Skipping it often means a small number of heavy users end up degrading the experience for everyone else.
Materialization is worth considering for queries that are complex, expensive, and based on data that does not change by the minute. When a workbook is pulling together many sources and the underlying data is stable enough that hourly or daily freshness is acceptable, pre-computing that result and caching it removes the cost of running the same expensive query repeatedly. For use cases where real-time data matters, live querying is appropriate and materialization adds complexity for no meaningful gain.
What should you do before you start implementing embedded analytics?
The technical work of embedding analytics into a product is not that hard. The platform handles the rendering, the query execution, and the warehouse connection. It cannot, however, retroactively redesign your data model, reconfigure your tenant isolation strategy, or renegotiate a licensing structure you did not think through.
A more useful question to ask before implementation work starts is what needs to be true about your data model, your tenant strategy, your performance architecture, and your vendor relationship for this to work well at the scale you expect to reach. Answering that question in a design document is much less expensive than answering it through a rewrite. When you’re ready to move into implementation, our embedded analytics documentation covers the step-by-step process from warehouse connection to production deployment.
To see how Sigma handles data modeling, tenant isolation, and performance architecture for embedded use cases, request a demo today.
Frequently asked questions
What is the most important thing to get right before implementing embedded analytics?
Data model design. The shape of your underlying data, whether it supports multi-tenancy, how much transformation happens before it reaches the analytics layer, and how comprehensible it is to people who did not build it, determines what your analytics layer can do and how much it will cost to operate. Most implementation problems that require significant rework trace back to a data model that was not designed with embedded analytics in mind.
What is the difference between row-level security and schema-level isolation for multi-tenant embedded analytics?
Row-level security restricts which rows a user can see within a shared table, based on their identity or attributes. It is flexible and scalable but requires careful, ongoing configuration and governance. Schema or connection-level isolation gives each tenant a separate data container, which provides a stronger security boundary at the cost of higher operational overhead as your customer count grows. The right choice depends on how your data is structured, how many tenants you expect to manage, and what your team's capacity for ongoing governance looks like.
When should embedded analytics use materialized results versus querying live data?
Materialization makes sense when the underlying data does not change frequently, the query is computationally expensive, and users do not need up-to-the-minute freshness. For dashboards reporting on last quarter's activity or weekly aggregates, pre-computing results can significantly reduce cost and improve load times. For use cases where users need real-time data to make decisions, live querying is appropriate and materialization adds complexity without meaningful benefit.
How should a SaaS company think about embedded analytics licensing costs as they scale?
Model it early and model multiple scenarios. Understand what drives costs under your vendor's pricing model, whether that is per-seat, per-query, per-feature tier, or something else. Then project what that means at your expected customer count, at higher-than-expected usage, and at the feature tier you intend to offer premium customers. Licensing costs that seem manageable in a pilot can reshape unit economics at scale if the structure was not understood before the contract was signed.
What typically breaks when you try to retrofit multi-tenancy into a data model that was not designed for it?
The analytics layer and the underlying application become tightly coupled in ways that make both harder to change. Access control policies get inconsistent because the data was not organized around tenant boundaries from the start. Performance often suffers because queries cannot efficiently scope to a single tenant's data. The fix usually requires rebuilding parts of the data model, which means downtime, migration risk, and retesting every downstream workbook that depended on the old structure.