Unlocking the treasure trove: harnessing unstructured data with Sigma's text processing tools

Unstructured data makes up a massive proportion of the information collected in our data-hungry world. For every structured data point such as a click, purchase, or sensor reading, you can count on that data point to exist within a much larger context of qualitative information.
Consider a single purchase on an online commerce site. The structured information that we may be able to collect can be quite comprehensive, including details such as the price paid, the shipping details, and the product info. But the unstructured text information—such as the customer reviews the shopper was exposed to, or the advertising copy that originally hooked our shopper, or the descriptions of the purchased product itself—represents the bulk of an iceberg that is almost by definition being neglected in a traditional analytic setting.
Because those data sources have not yet been parsed and categorized into clean and clear variables for exploratory analysis, they remain unstructured and most likely untapped.
Today’s data platforms provide us with the ability to store a virtually limitless amount of these unstructured fields, but exploring them as an end user can be overly technical and inaccessible.
Thankfully, Sigma’s out of the box text processing capabilities make it a breeze to connect directly to these unstructured data sources and start mining them for the gold within!
Example data structures
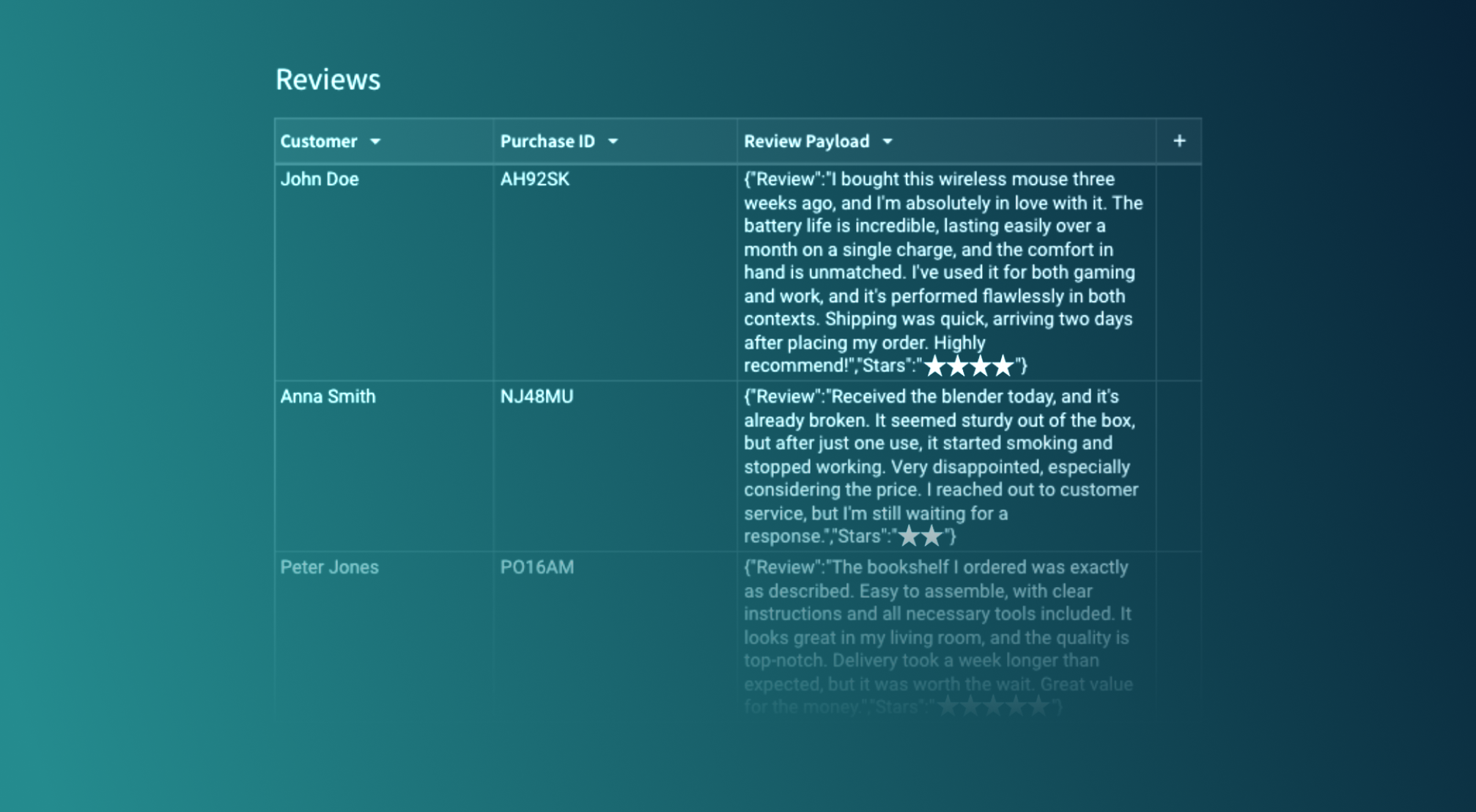
An overview of unstructured data
Sigma can connect to a variety of data. For example, here is a table in a fictitious dataset that has a set of three customer reviews.

This example contains three reviews with a rich set of details—not just about the product—but also their experience on the site and with the customer service.
Working with all unstructured data comes with one giant challenge—there is no consistency in how information is conveyed. This makes it difficult to flag or analyze any patterns.
Sigma makes working with unstructured data simple by natively connecting to unstructured text—and then making it easy to explore with traditional analysis, generative AI and machine learning capabilities.
How to to connect to unstructured data in Sigma
Unstructured text is usually stored in a popular file format called JSON. JSON, which stands for JavaScript Object Notation, is a lightweight data interchange format.
With JSON, data is structured into key-value pairs.
If this is your first time hearing about JSON, it’s structured a bit like this:
{
"reviews": [
{
"id": "1",
"review": "You’ve got to try the chicken",
"stars": "5"
},
{
"id": "2",
"review": "Service was okay",
"stars": "3"
},
{
"id": "3",
"review": "It was raining when we went there",
"stars": "1"
}
]
}
The JSON file starts and ends with curly braces {} indicating an object. Inside this object, there's a key named "reviews" that maps to an array—or group—of review records. Each element within the employees array is an object representing a single review, with key/value pairs describing the review's id, the review, and total stars of the experience.
Sigma easily connects to JSON and parses it using the “Extract Columns” feature, and lets us select the fields we care about. This feature saves us from having to programmatically extract these values, giving us more time to explore the data itself.

How to analyze unstructured data in Sigma
Let’s look at three different ways Sigma can extract value from your unstructured text:
These methods are all designed with the end user in mind and should be accessible to people with even the smallest amount of Excel experience!
Dynamic text analyzer
The first thing we might be interested in is the actual object of the review itself. We know what our products are, and we may want to search for those products within the review so that we know what our customer is talking about. We’ll be using a Sigma custom function that my data team has built behind the scenes so that I can easily run this operation without worrying about the syntax.

We’ve been able to identify 2 of our products in the reviews. A quick read of the review that hasn’t been categorized tells me it’s about a wireless mouse. Let’s add that to our input table so that we will pick this up in future reviews:

In this way, we can continually iterate on our analyzer so that we will be able to capture more and more product information from the review.
ML sentiment analysis
Using Machine Learning to analyze the sentiment of unstructured text is a very popular method for deriving an actionable insight from customer feedback. To do this, NLP algorithms extract relevant features from text, such as words, phrases, or context, followed by running a ML model which has been trained to classify subjective information into sentiment categories (positive, negative, or neutral). Quite a mouthful for your average analyst! In Sigma, you can have your Data Science team deploy such an algorithm within your cloud data warehouse, and then give you a simple, Excel-style formula that can make the hard stuff simple:

Our NLP algorithm is effectively categorizing our positive reviews, and finding the negative sentiment in Anna Smith’s review, where their blender immediately broke 😿.
Generative AI to parse the text
It wouldn’t be a 2024 tech article if we didn’t talk about AI! In Sigma, we can call personalized, powerful Gen AI models from your cloud data warehouse, and make it possible for you to directly ask questions from your data. The benefit of this method is that you won’t be confined to the output categories like we were in the sentiment analysis, and you’ll be able to iterate on the precise information you are looking for.

In our example, my prompt asks for an action that I could take to improve in the future. My CDW will then parse that prompt through a Gen AI model of my choice, and give me output in a format that I can control. If I need further refinement, I could work with my data team to fine-tune the model that I am using so that it’s tailored perfectly to my unique business case, such as reviewing financial statements or call transcripts.
Summary
Now that I’ve applied these three techniques, I can now analyze my reviews just like I’d analyze any other structured data in Sigma. I can use a Lookup to tell me how much revenue each product type brings in, so that I can prioritize the reviews based on how much their matched product brings in. I can filter my reviews to just the Negative sentiments for those high reviews. And now, I have a direct action I can take to try and improve my customer experience! In short, with a few formulas and filters, I’ve just created a plan to boost my highest priority product.

Businesses are increasingly turning their attention to unstructured text as a way to get an edge on the level of analytics that they can run on their operational data. At Sigma, we’re committed to getting those analytics functional, accurate, and accessible. If you’re interested in finally getting value out of your unstructured data, I hope these examples have got you thinking about how you could use Sigma yourself!
Get in touch with us to see a demo or get started on a free trial.
Sign Up to Get Sigma in Your Inbox
By submitting, you consent to allow Sigma Computing to store and process the personal data from this form to fulfill your request.